
L’Algorithme de matchmaking sur League of Legends
Castor Orange | Publié le |

L’algorithme de matchmaking dans League of Legends, si vous jouez au jeu, vous en avez très probablement déjà entendu parler. Mais au fond qu’est-ce que c’est ?
Dans cet article, nous allons nous pencher sur les différentes questions que soulève l’algorithme de matchmaking de League of Legends. Et cela, tout particulièrement à travers un axe récurrent concernant ce sujet : l’algorithme favorise-t-il les séries de victoires ? Avant d’y répondre, nous nous pencherons d’abord sur le fonctionnement général du matchmaking. Par la suite, nous verrons comment nous avons pu modéliser les résultats de plusieurs milliers de parties à partir d’un simple lancer de pièce. Enfin, nous discuterons des résultats obtenus et ce qu’ils révèlent sur les coulisses de l’algorithme.
Principes & généralités de l'algorithme
Tout d’abord, petit point sur le fonctionnement des parties classées de League of Legends. Si vous êtes familier avec le jeu, vous connaissez très probablement le système de MMR (Matchmaking Rating). Ce chiffre caché, lié à chaque compte, croît ou décroît selon le résultat de vos parties classées. Plus votre MMR est grand devant votre rang affiché, plus vos gains de LP seront conséquents (et inversement). Ce système de classement reprend le principe d’Elo des échecs basé sur la force relative des différents joueurs qui s’affrontent.
l'Algorithme équilibré : le SBMM
Une question se pose donc : comment les joueurs sont-ils appareillés au sein d’une même partie ? Le premier critère est de regrouper les joueurs par zone géographique pour limiter les soucis de latence, d’où la présence de serveurs. Le second critère intuitif est de répartir les joueurs selon leur niveau de jeu de telle sorte à avoir des games équilibrées. Ce principe d’appariement s’appelle le SBMM pour Skill Based Matchmaking. Si d’un point de vue compétitif cet appariement est idéal, des limites demeurent. Par exemple, il y aurait un certain manque de diversité dans les games, ce qui pourrait favoriser la lassitude des joueurs. Contrairement à ce que l’on pourrait penser, l’équilibre d’un jeu n’est pas ce qui le rend plaisant.
l'algorithme optimisé : l'eomm
En effet, un certain nombre de jeux ont mis en place un matchmaking favorisant l’engagement : l’Engagement Optimize Matchmaking (EOMM). Assez proche du SBMM sur le principe, il a cependant pour objectif d’optimiser le sentiment de frustration/récompense chez le joueur. Pour cela, l’EOMM va faire en sorte que les joueurs alternent entre les victoires et les défaites à une certaine fréquence. C’est ce principe qui est à l’origine de nombreux fantasmes, certains arguant que des games sont ingagnables, d’autres que cela favorise les séries de victoires et de défaites. Cependant, si ces idées existent, c’est bien parce que l’algorithme de matchmaking est une véritable boîte noire. Nous allons ici essayer de mettre en lumière certains points du fonctionnement de l’EOMM de League of Legends.
Par définition de l’EOMM, oui, des parties seront plus dures à gagner que d’autres. Effectivement, toutes les games ne seront pas du 50-50 comme cela devrait être le cas pour un SBMM parfait. Toujours dans l’idée de favoriser les cycles de frustration/récompense, il est bien plus intéressant d’avoir des games « plus difficiles » mais largement gagnables que des parties véritablement ingagnables du point de vue du matchmaking. Et en moyenne, vous aurez autant de ranked dites « difficiles » que « faciles ». De même, l’algorithme ne va pas favoriser des séries de victoires, ces séries tendant elles-mêmes vers les valeurs attendues selon votre winrate.
Modéliser les parties par un lancer de pièce truquée
Mais comment peut-on donc affirmer cela ? N’ayant pas accès au code derrière le matchmaking de RIOT, nous ne pouvons donc ici qu’analyser les résultats des parties des joueurs et les comparer à un modèle théorique. Pour ce faire, nous allons utiliser un des modèles les plus simples possibles : celui d’un lancer de pièce truquée. Pourquoi truquée ? Vous allez vite comprendre.
L’idée n’est pas de dire qu’une game est un lancer de pièce, cela serait indubitablement absurde. En revanche, si vous faites suffisamment de parties, on peut faire l’hypothèse que vos résultats seront sensiblement similaires à des lancers de pièces successifs. Les joueurs n’ayant pas nécessairement un winrate de 50%, la pièce est truquée pour coller au taux de victoire de chaque joueur. Nous nous intéresserons ici aux séries de victoires des joueurs que nous comparerons aux séries de face (succès) du lancer de pièce.
joueurs étudiés
Comme mentionné précédemment, un point clef est de choisir des joueurs avec suffisamment de parties et pour cela, rien de mieux que le top ladder. Nous nous pencherons sur les séries de victoires sur la Saison 12 de 22 joueurs du top ladder (données issues de l’API Riot) et de 8 joueurs Solary (données fournies par MrLeRandom). Tous ensemble, ces 30 joueurs cumulent pas moins de 19 000 games sur la saison 12.
| Pseudo | Nb. de parties | Winrate (%) | Pseudo | Nb. de parties | Winrate (%) |
|---|---|---|---|---|---|
|
974 |
53.9 |
314 |
61.8 |
||
|
775 |
55.9 |
303 |
60.4 |
||
|
390 |
57.2 |
606 |
54.8 |
||
|
765 |
54.1 |
381 |
56.2 |
||
|
652 |
55.8 |
667 |
54.0 |
||
|
570 |
55.4 |
384 |
55.0 |
||
|
409 |
57.2 |
384 |
56.2 |
||
|
232 |
53.4 |
398 |
55.3 |
||
|
474 |
55.7 |
788 |
53.6 |
||
|
616 |
54.2 |
579 |
53.5 |
||
|
593 |
54.5 |
433 |
54.5 |
||
|
963 |
51.8 |
756 |
51.5 |
||
|
852 |
50.5 |
645 |
51.0 |
||
|
818 |
50.7 |
995 |
50.6 |
||
|
1981 |
50.5 |
794 |
51.3 |
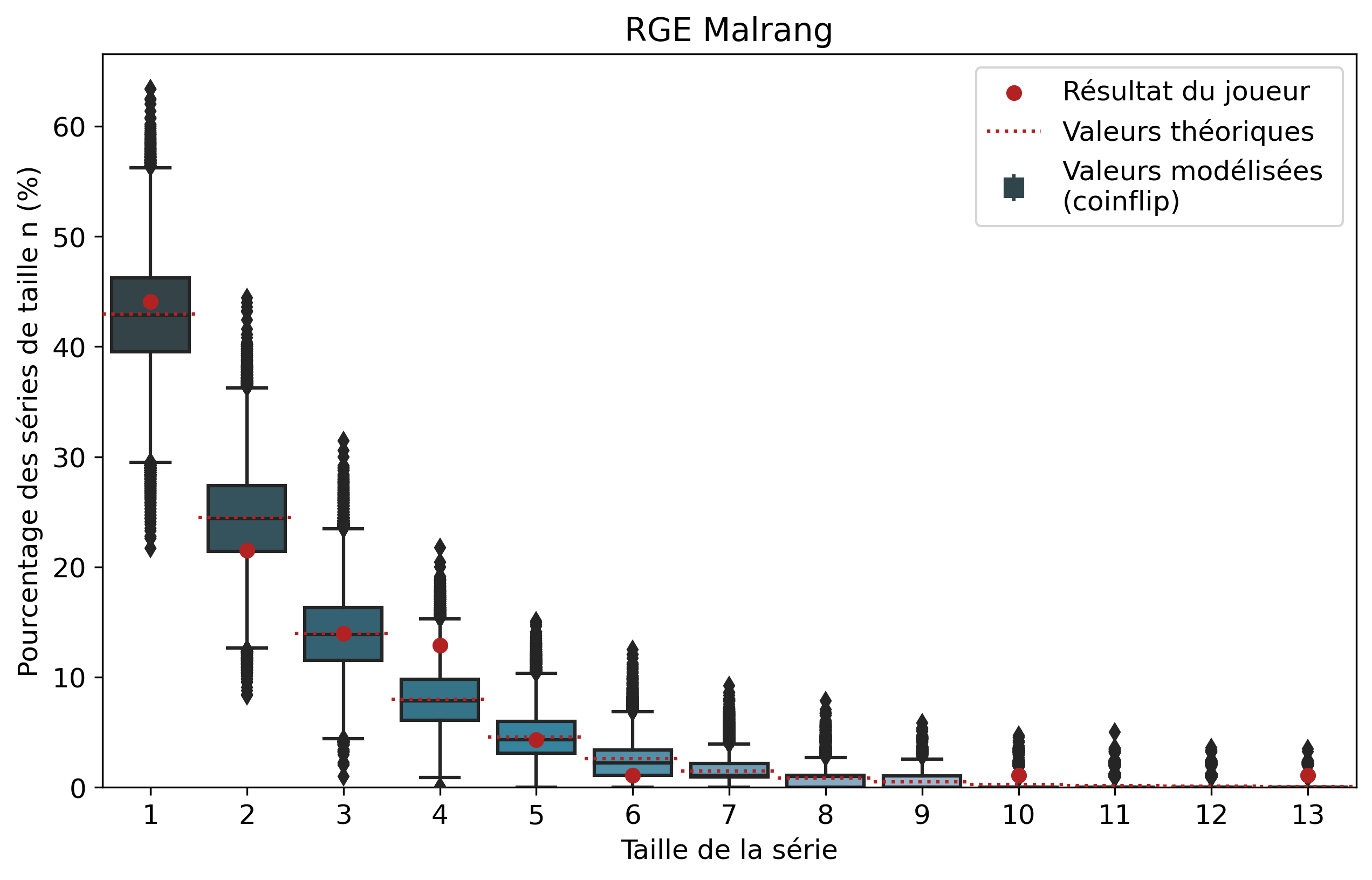
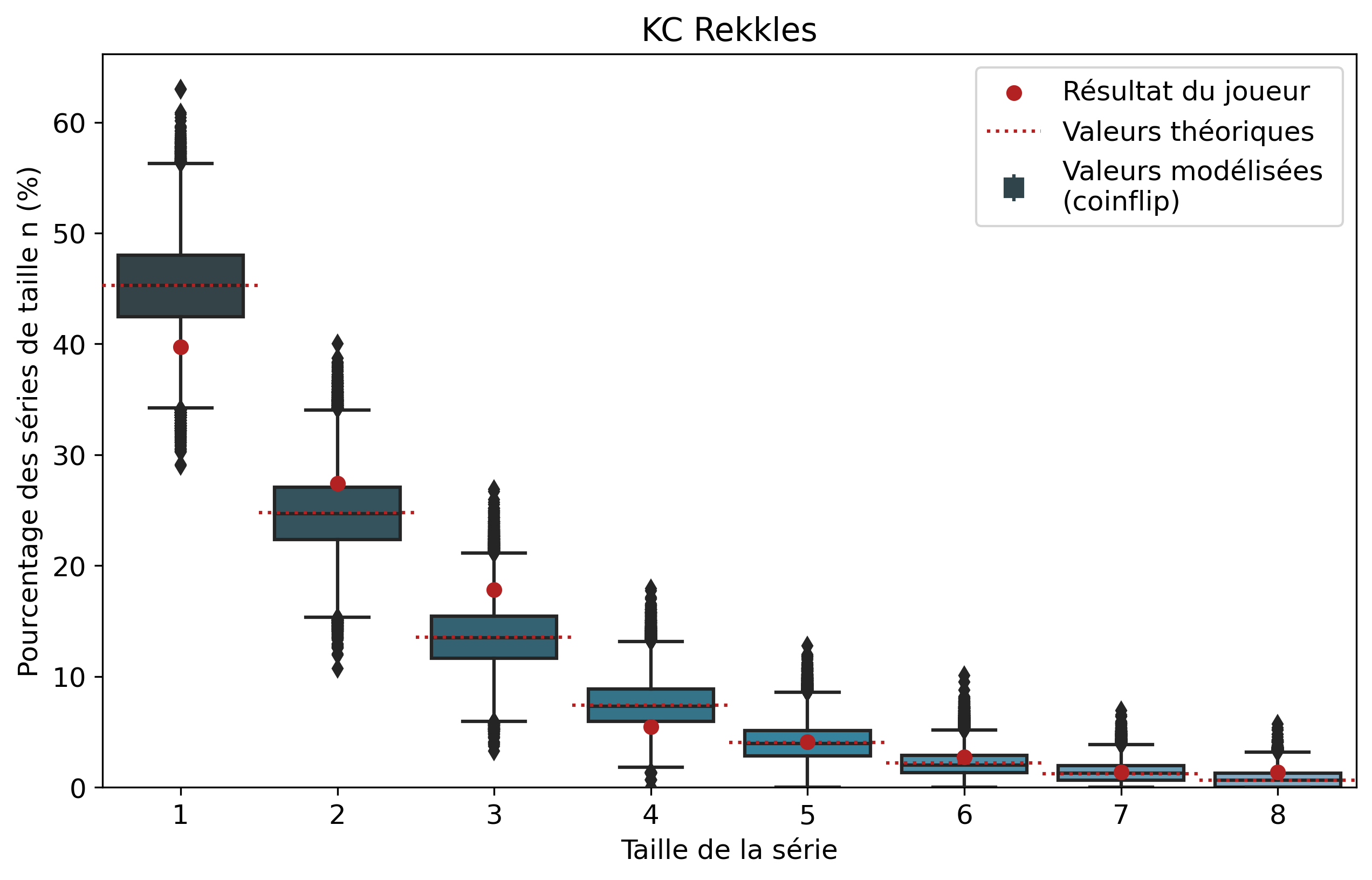
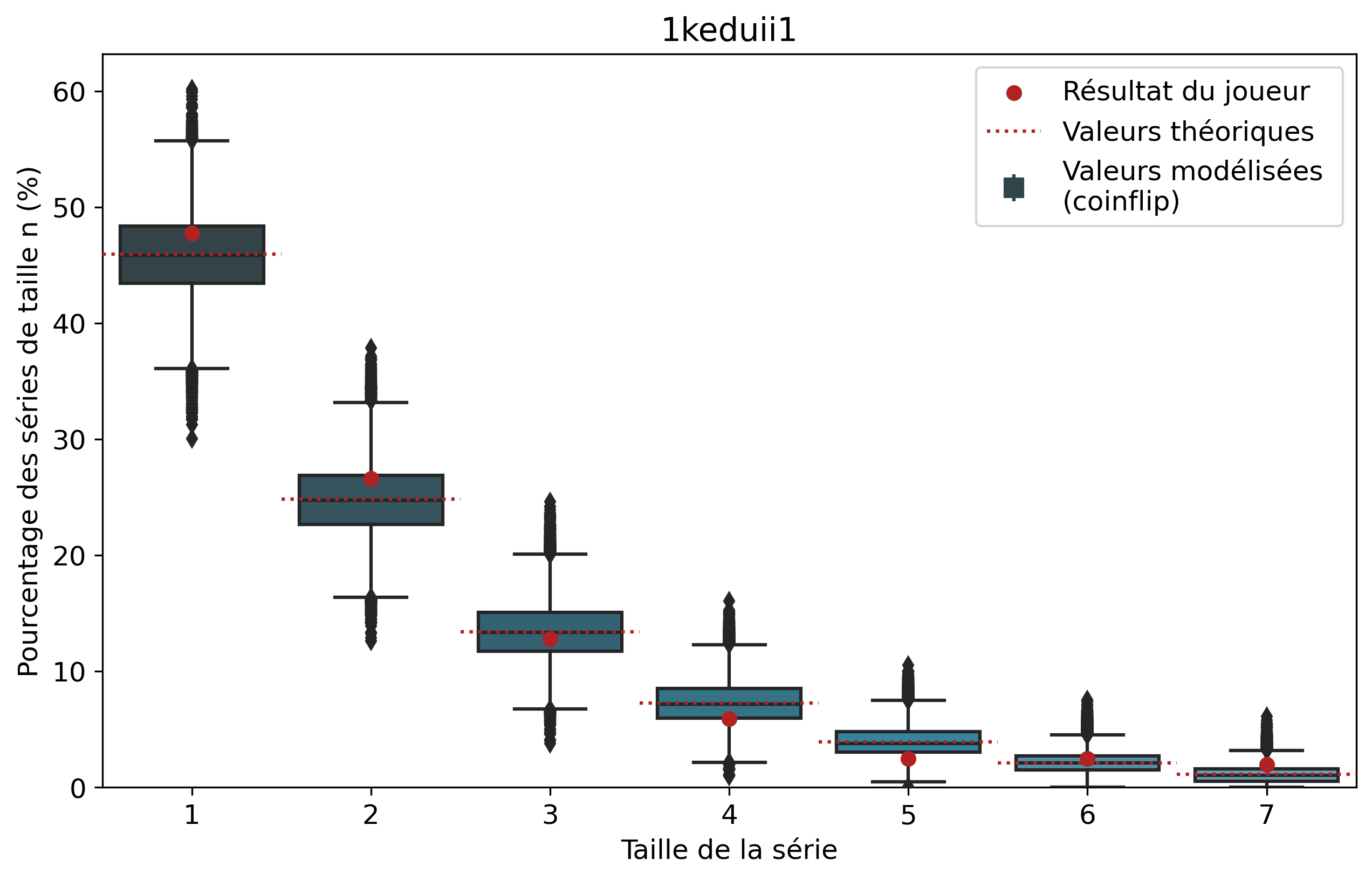
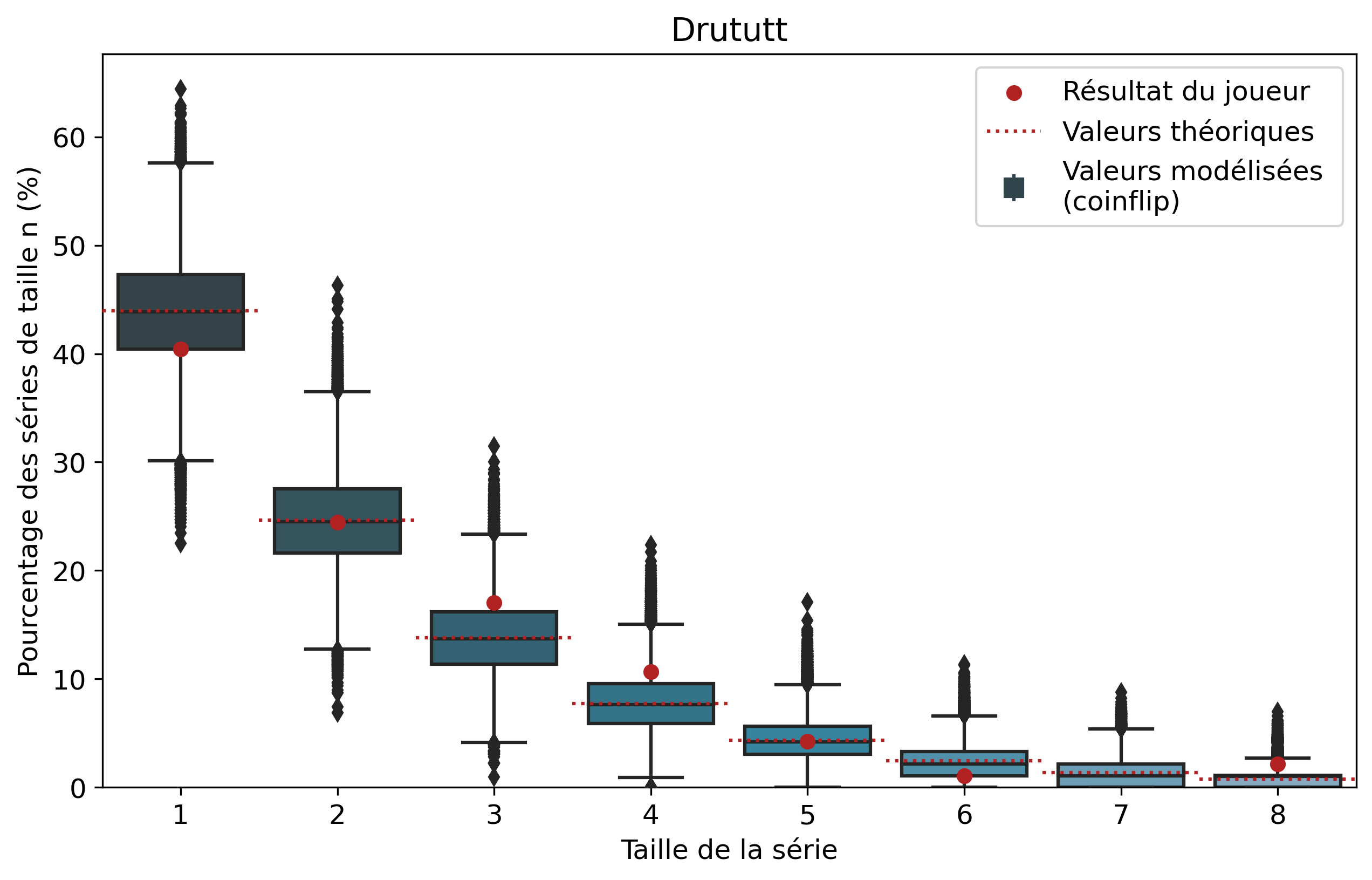
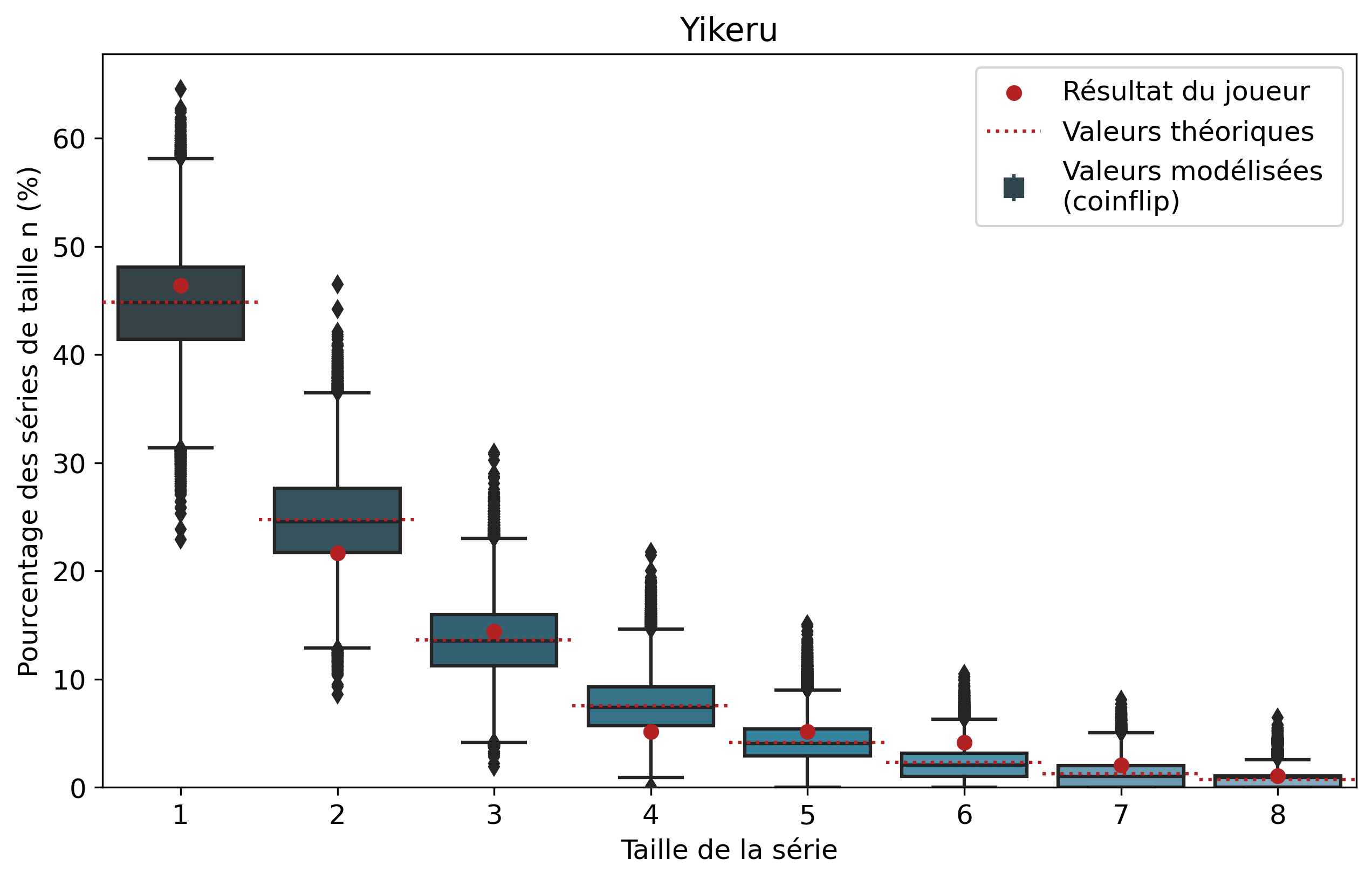
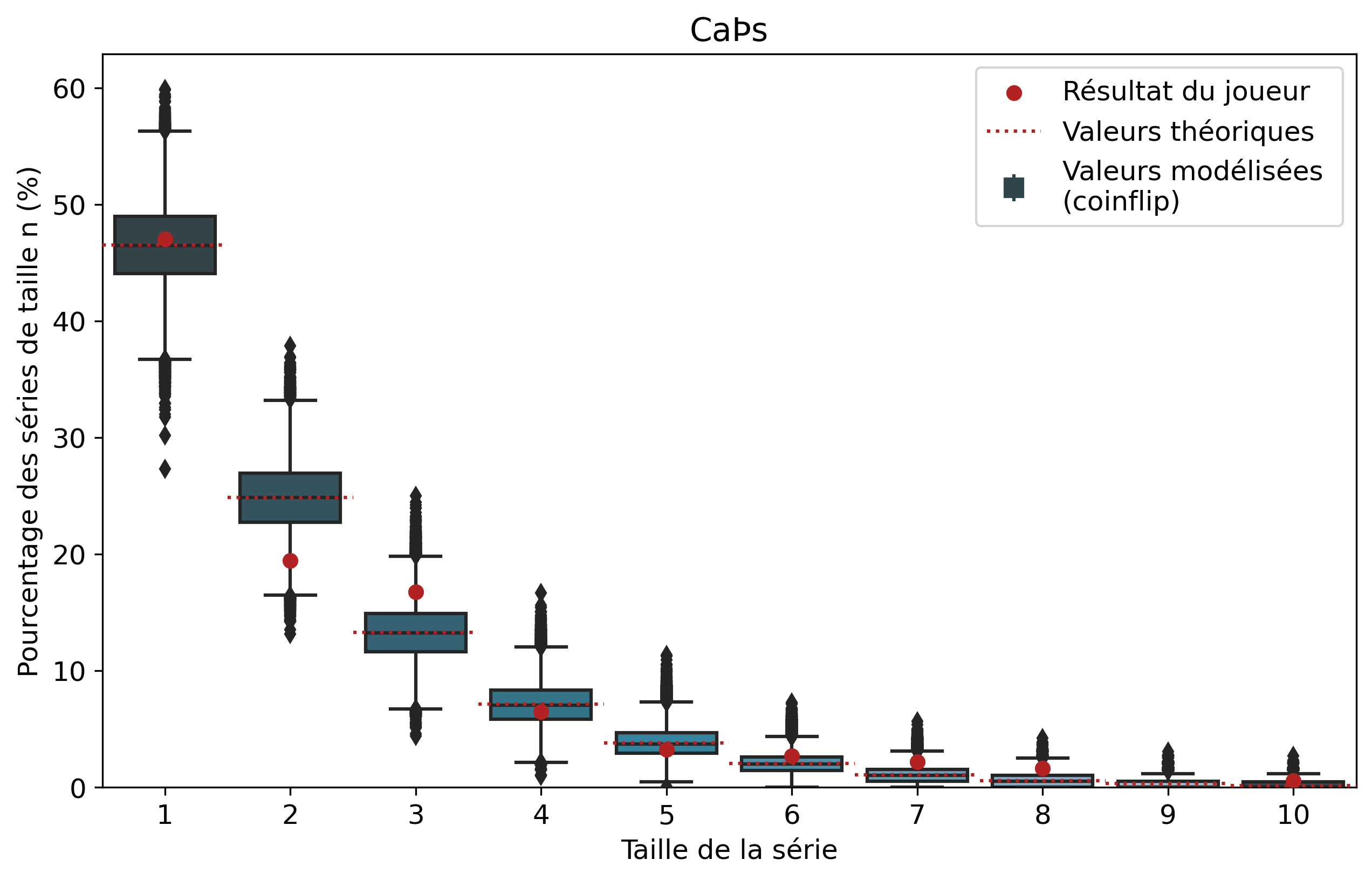
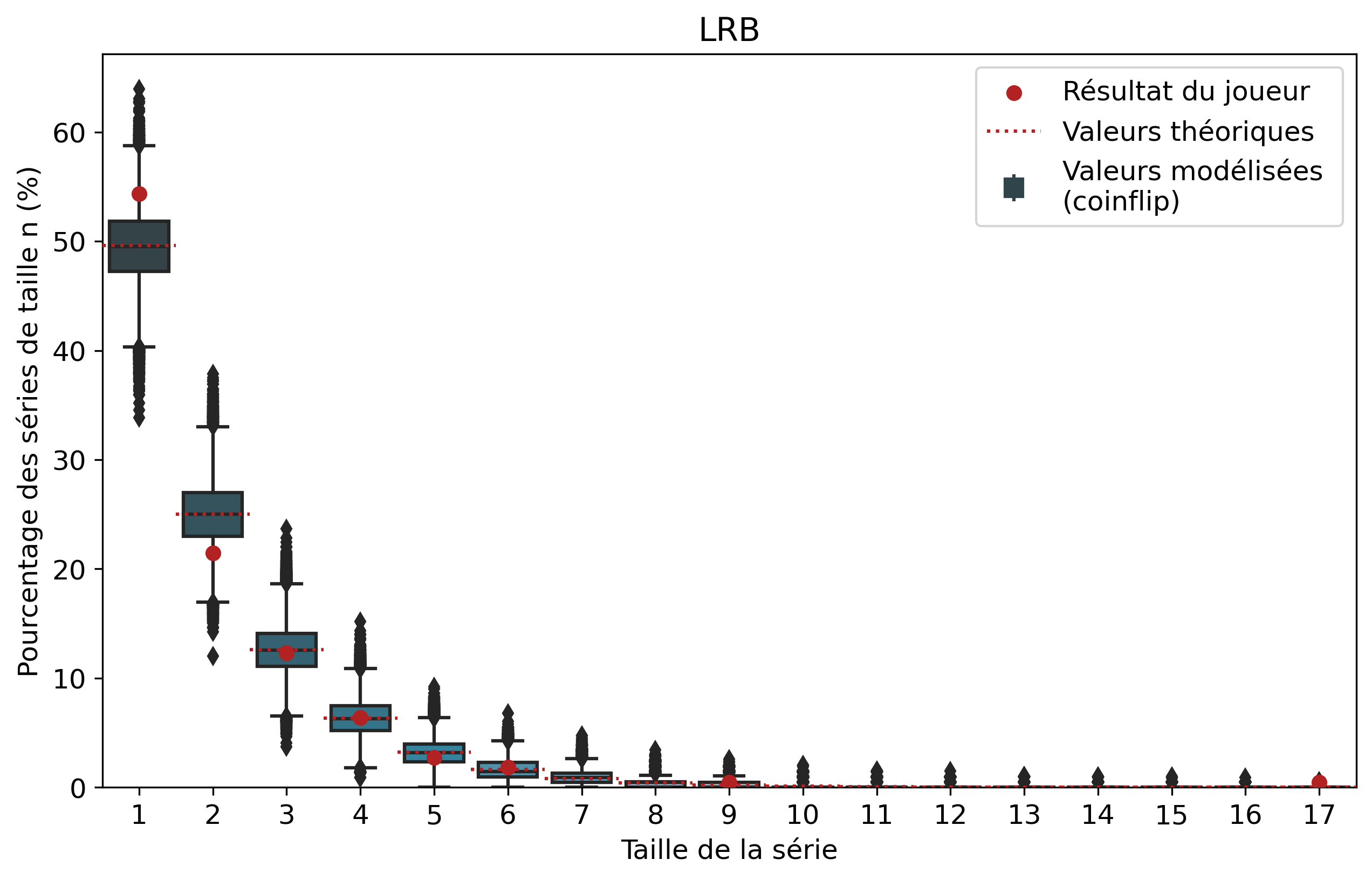
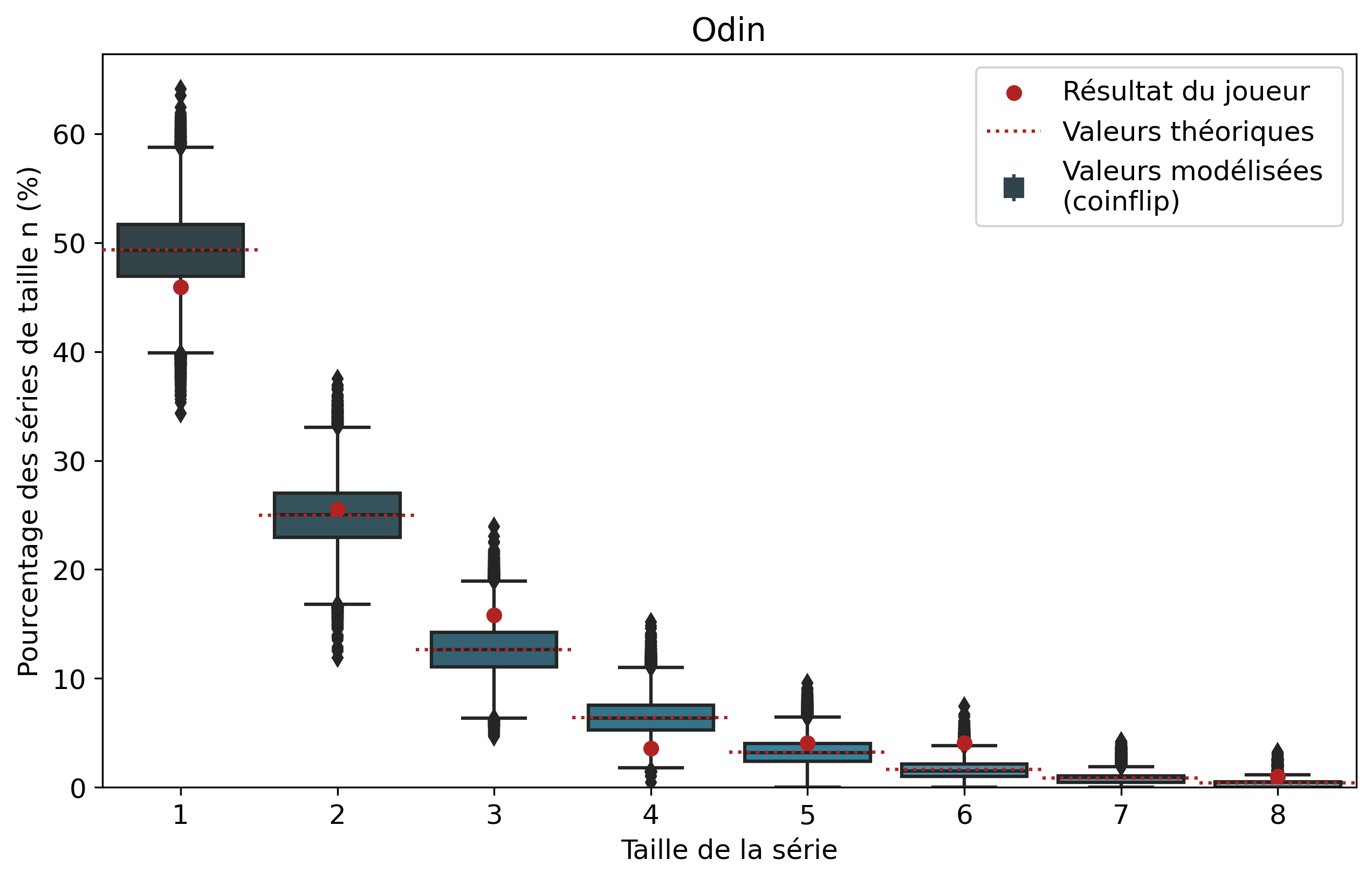
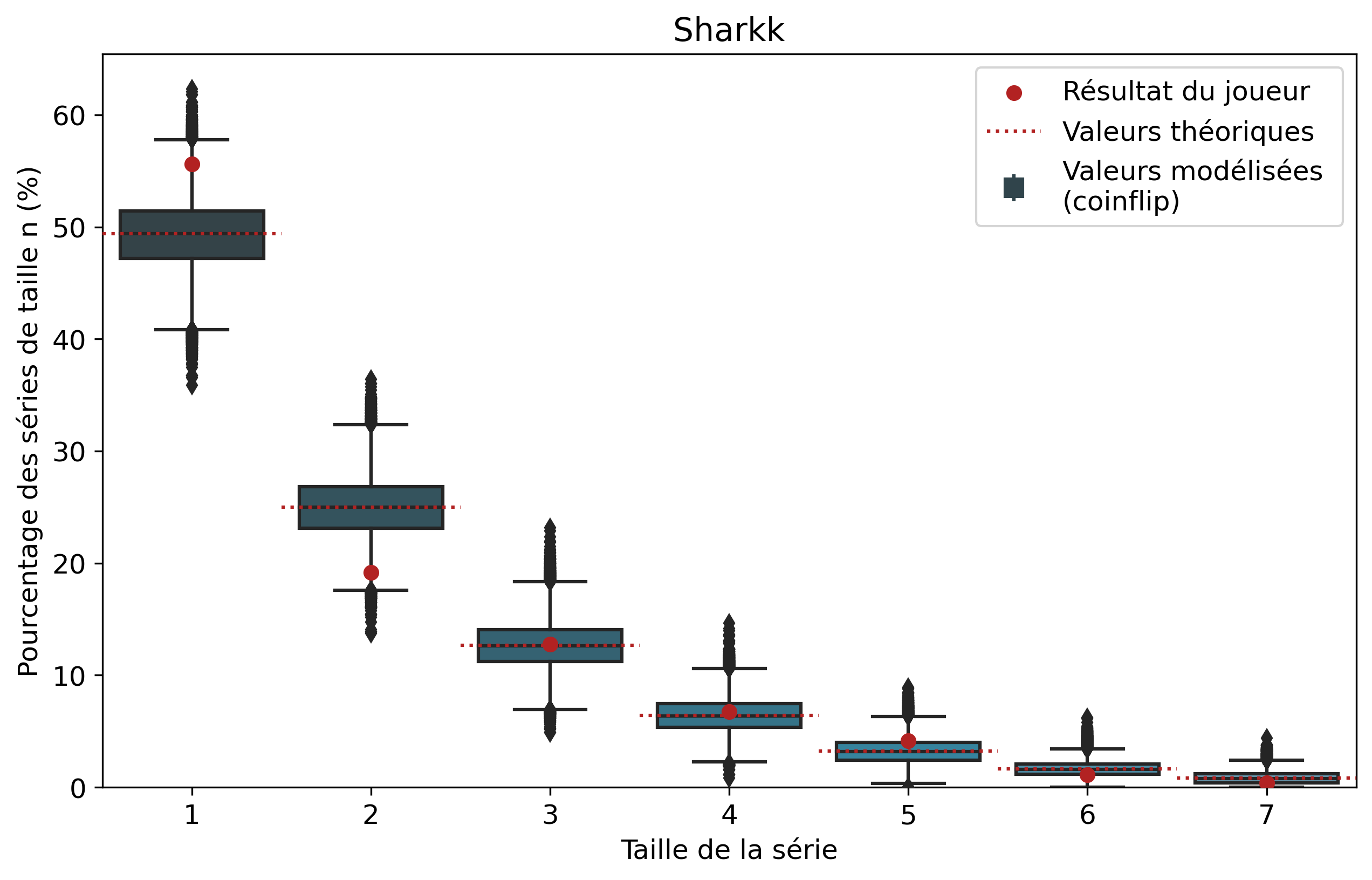
Nous allons nous intéresser aux séries de victoires de joueurs que l’on comparera aux séries de faces. À l’échelle d’un joueur, un certain nombre de biais demeurent tels que son playstyle ou sa résilience face au tilt. Il demeure intéressant de comparer les résultats pour voir si notre modèle est cohérent et si certains joueurs ont réalisé des séries de victoires que l’on pourrait considérer comme « improbables ». Nous n’allons pas rentrer dans les détails de tous les joueurs, mais si vous êtes curieux, les graphiques par joueur sont disponibles dans le tableau précédent d’un simple clic sur le pseudo.
Fonctionnement du modèle
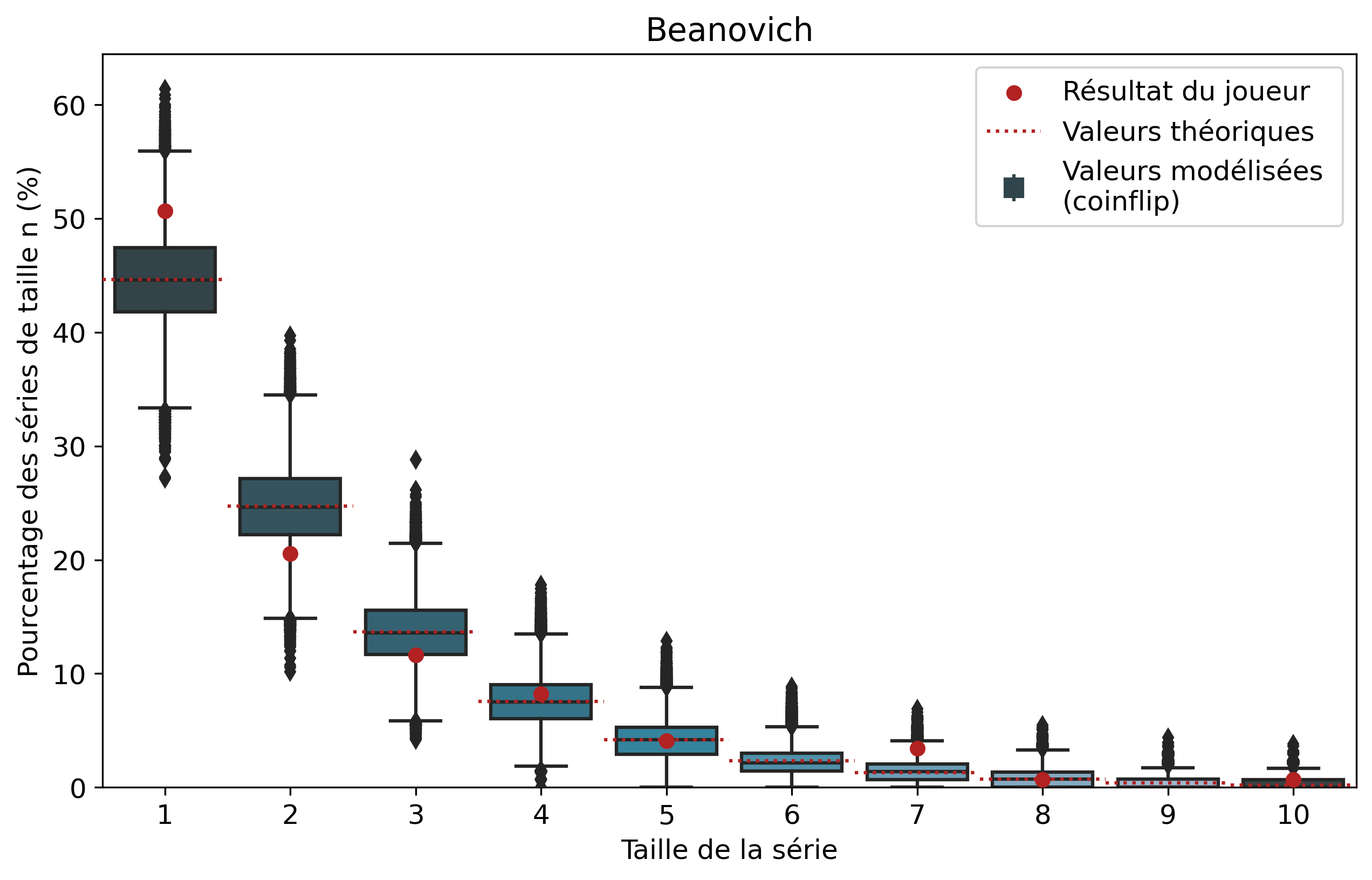
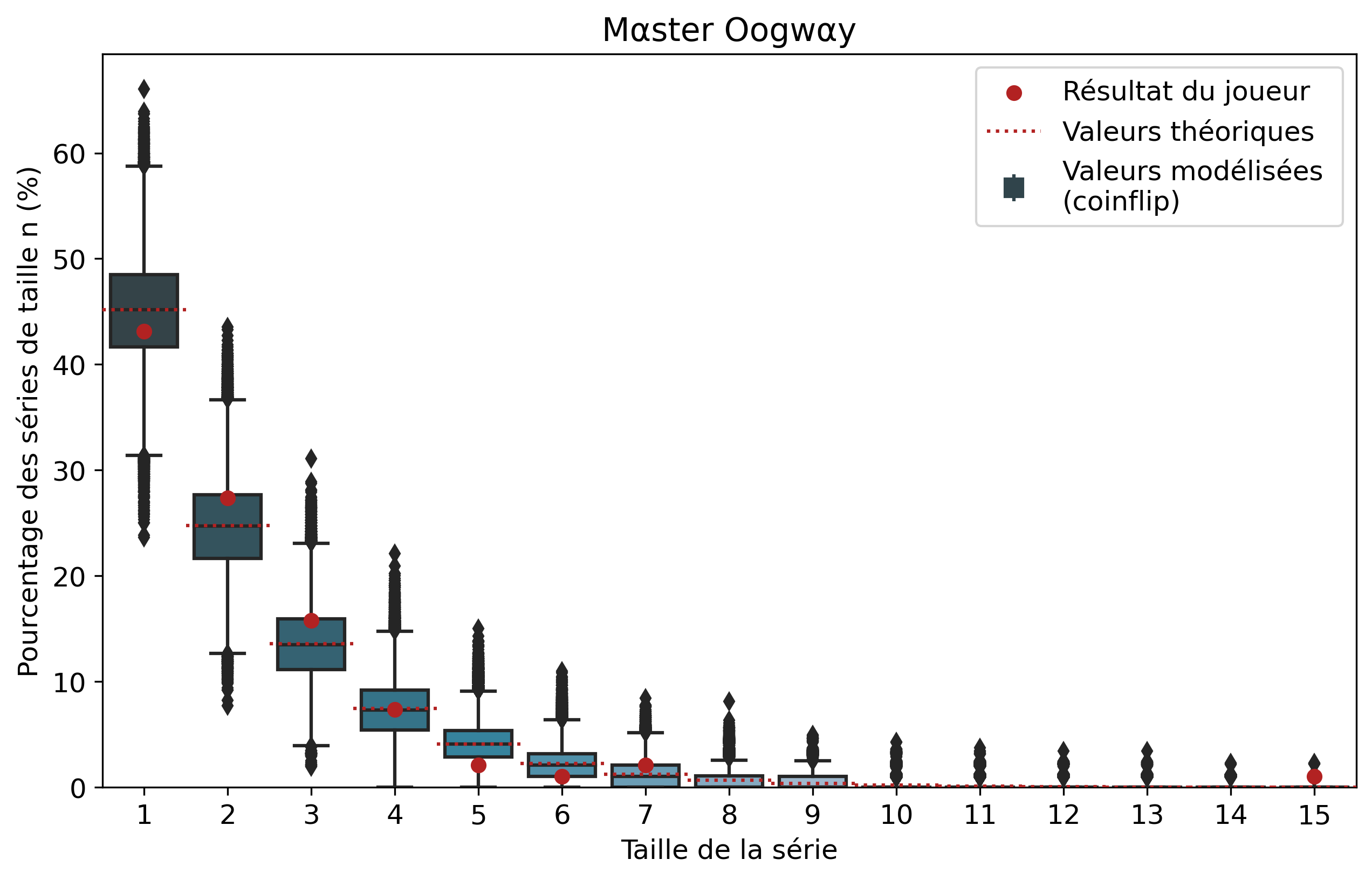
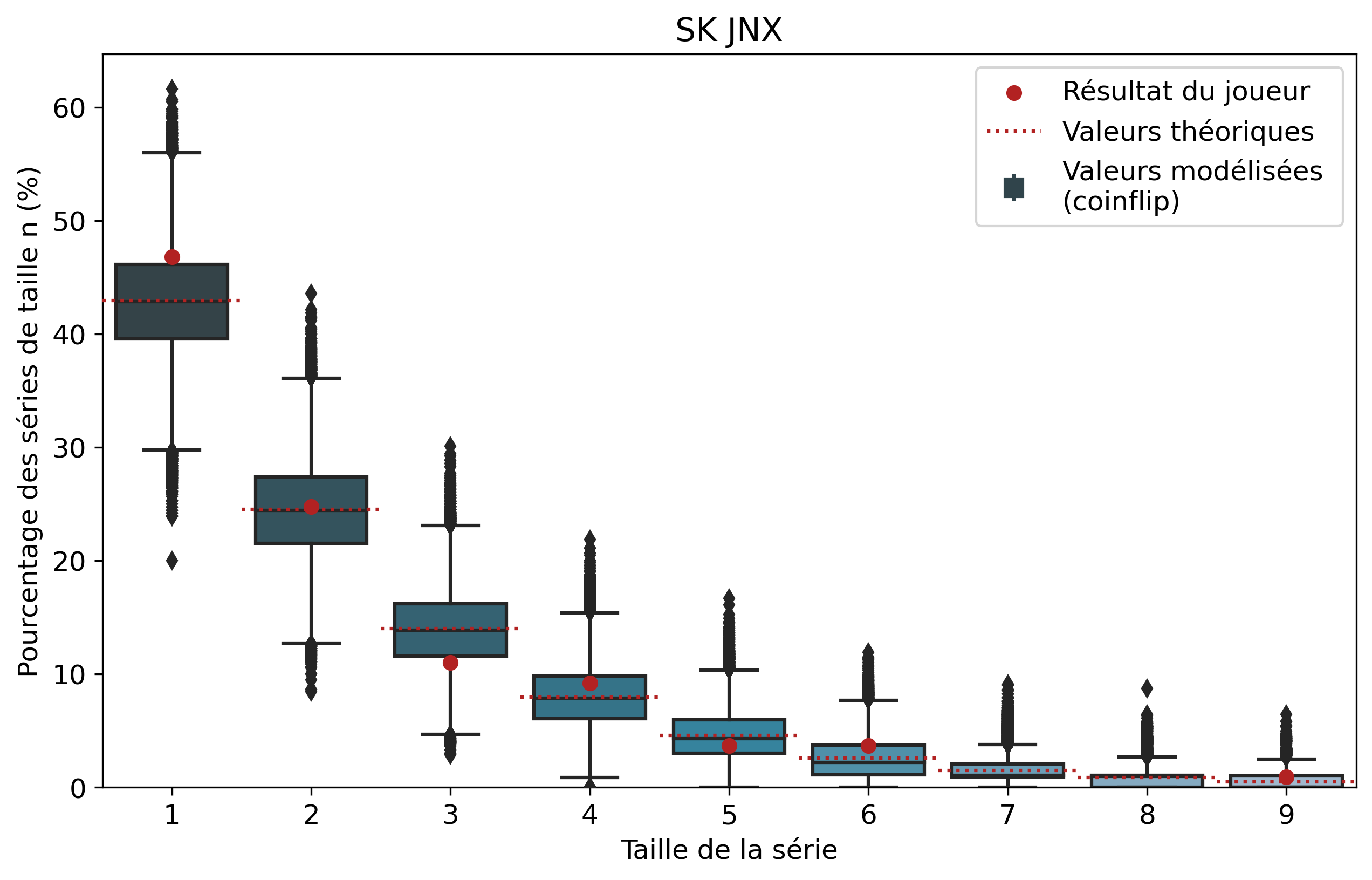
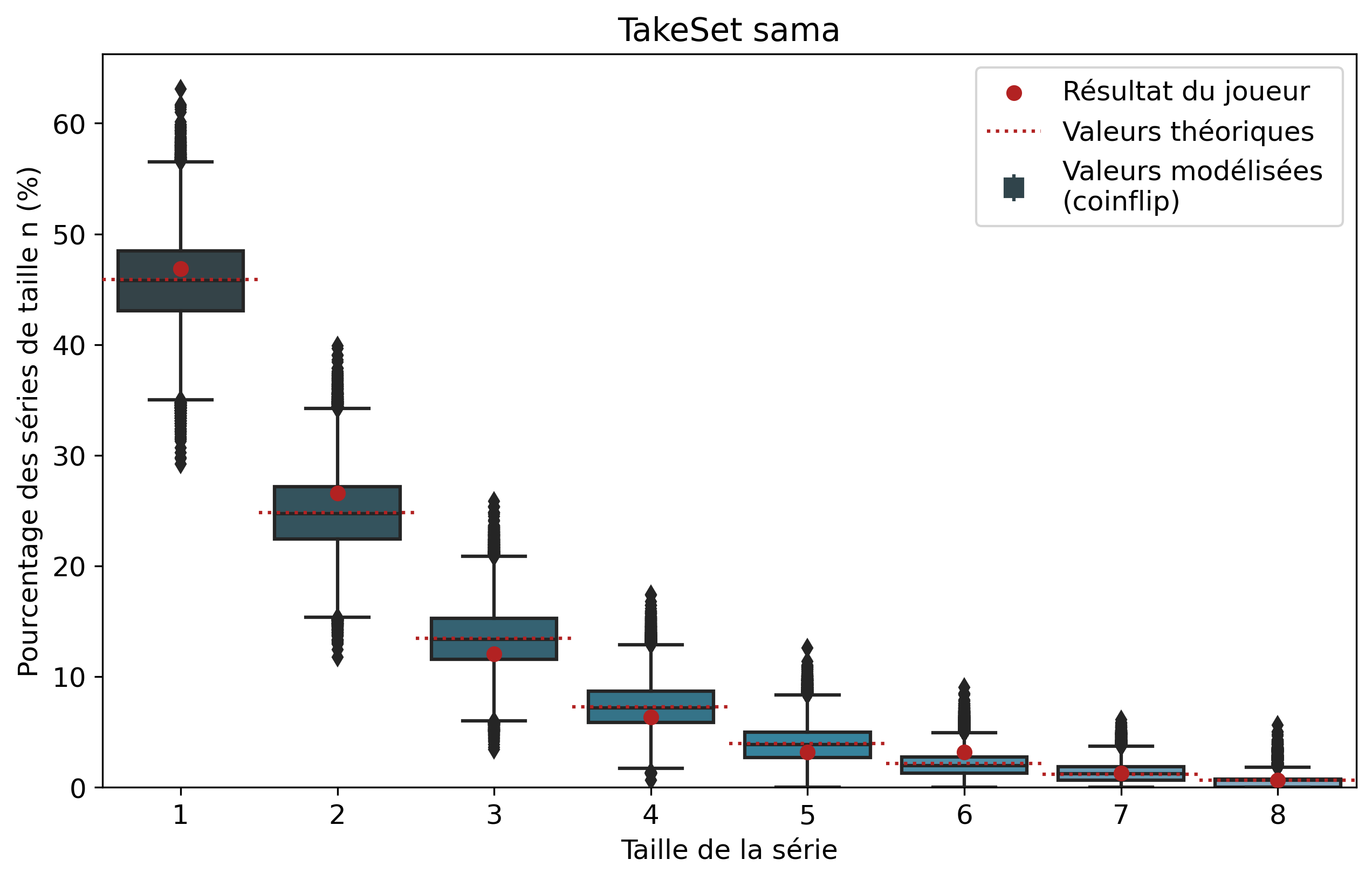
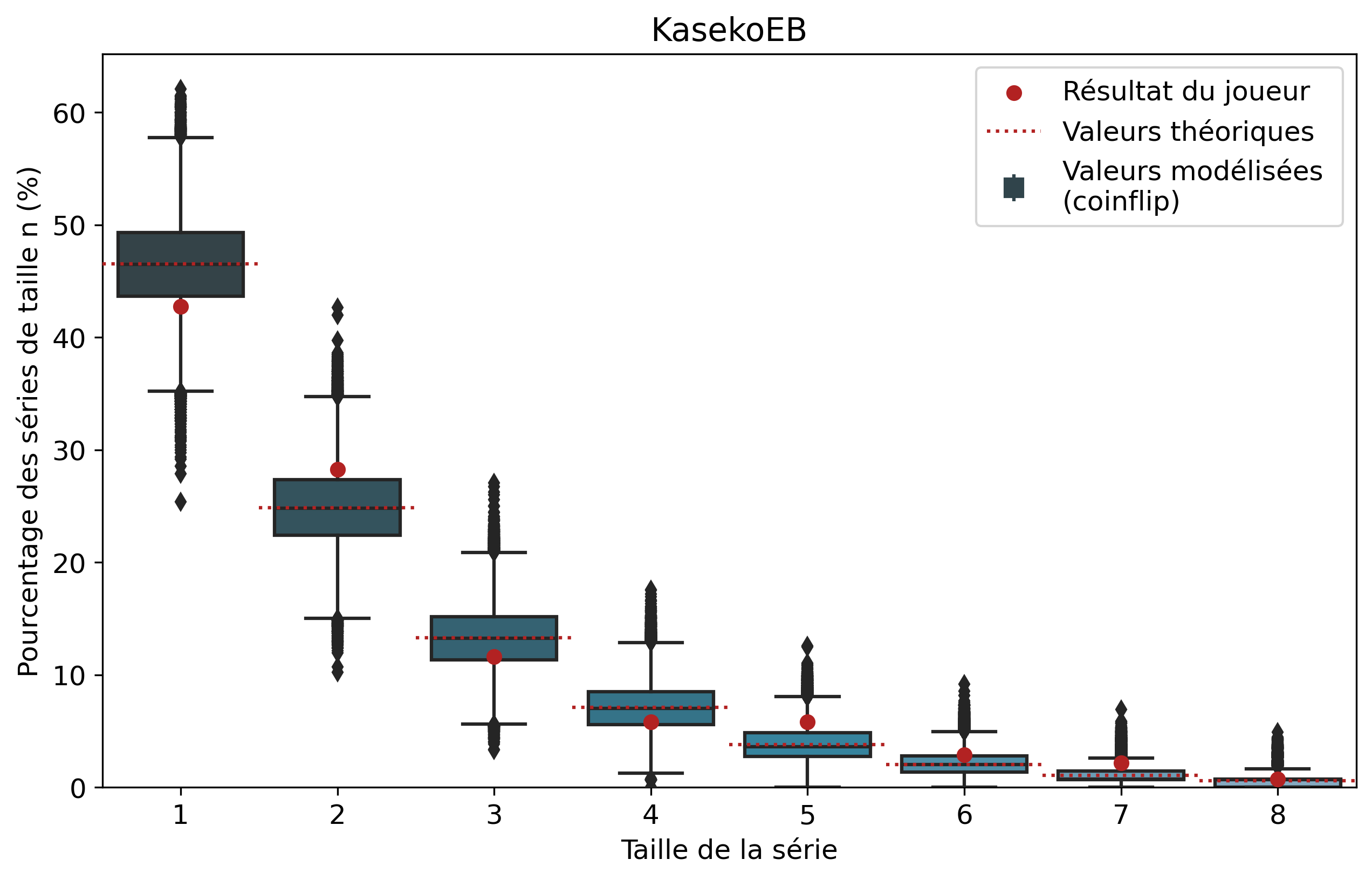
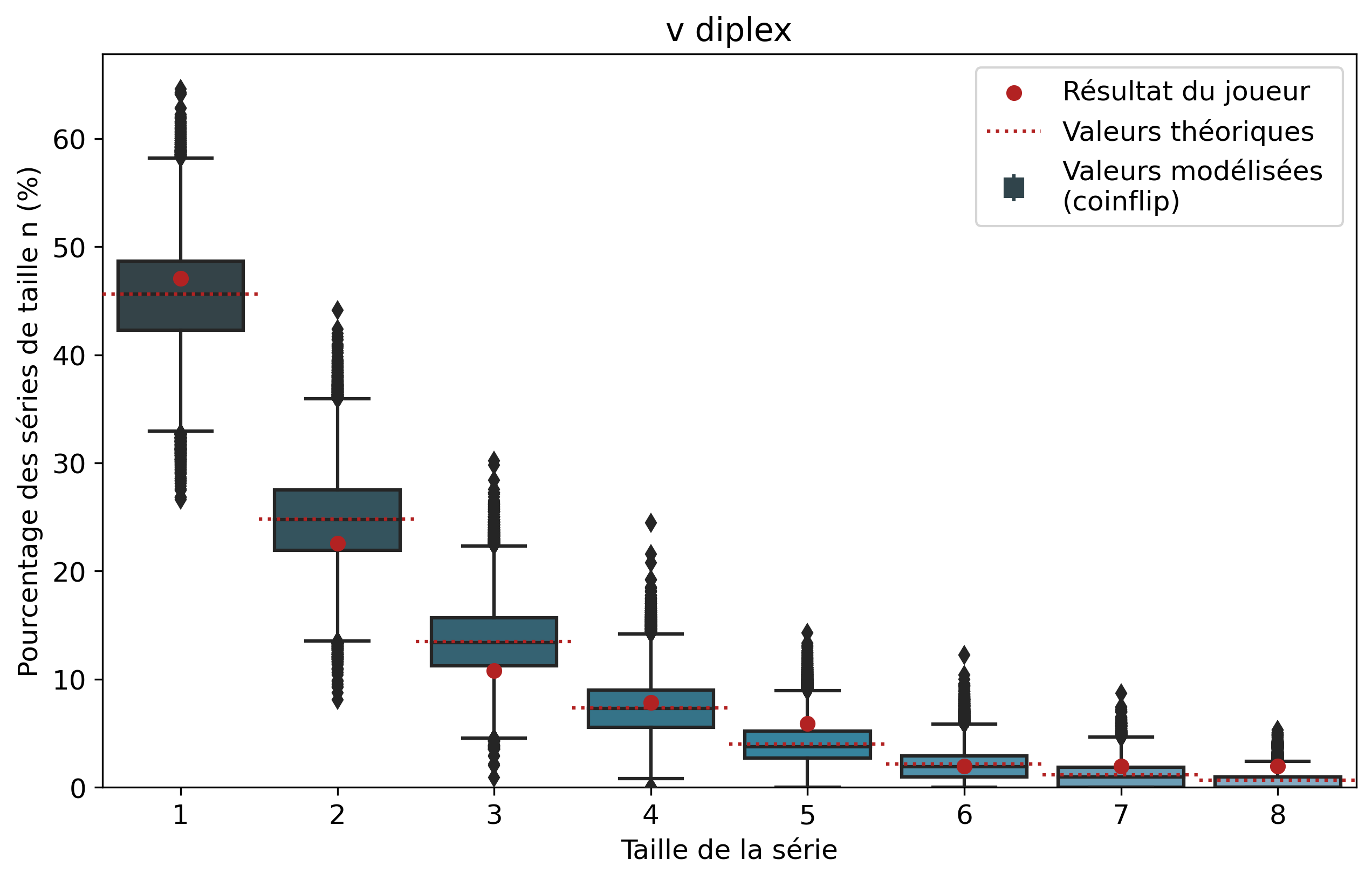
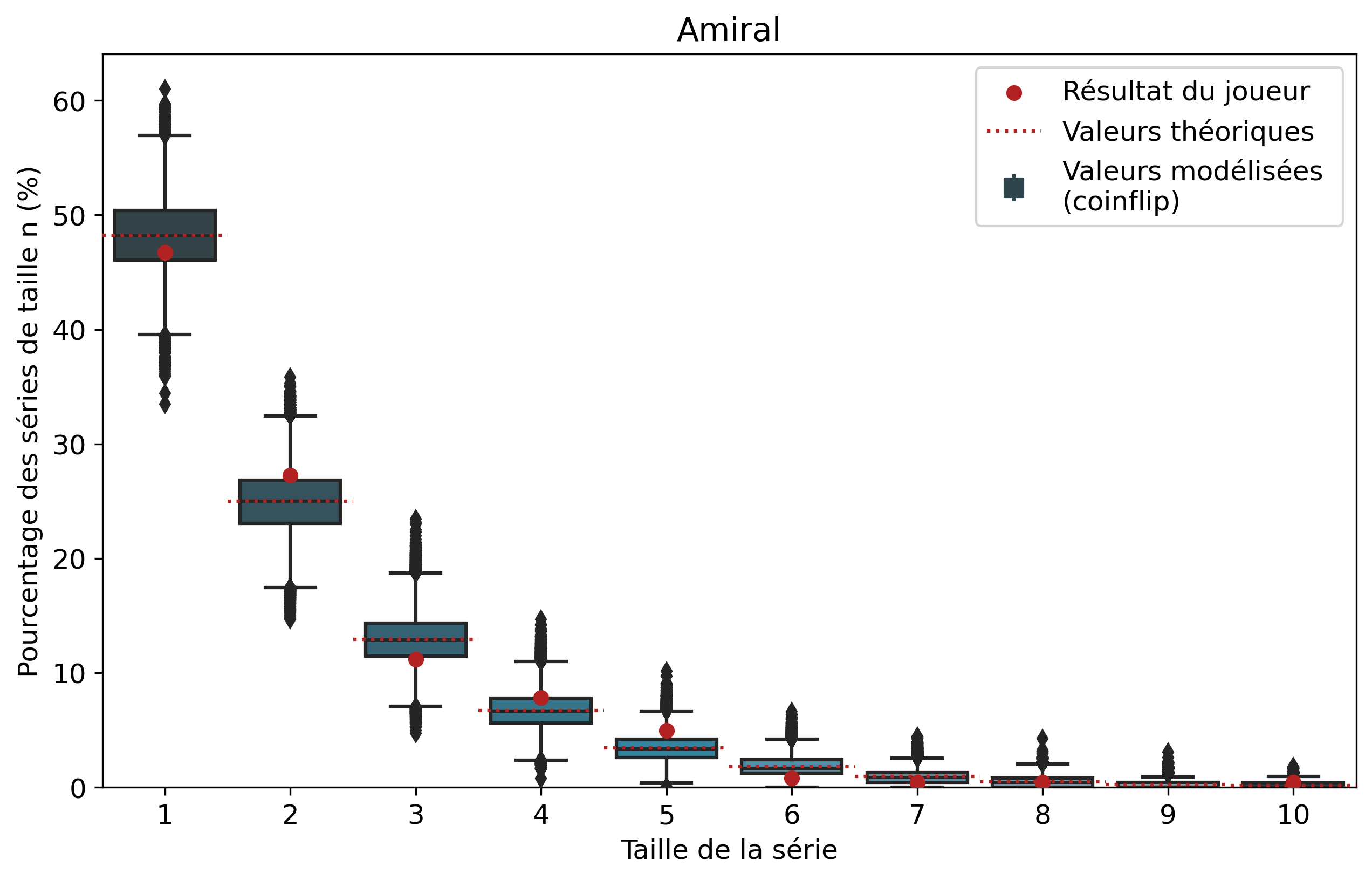
Ainsi, pour chaque joueur, l’ensemble de ses séries de victoires et leur nombre d’apparitions sont récupérés. Par exemple, pour Nisqy, on compte 72 séries de 1 victoire, 34 de 2 victoires, 20 de 3, etc. En parallèle, on détermine le nombre P de parties jouées par le joueur ainsi que son winrate. Ces deux valeurs constituent les paramètres du modèle de lancer de pièce truquée. D’une part, on réalise 50 000 scénarios de P lancers permettant de déterminer l’intervalle du nombre d’apparitions de la série de longueur n. D’autre part, par calcul, on détermine le nombre moyen d’apparitions de la série de longueur n pour les paramètres donnés.
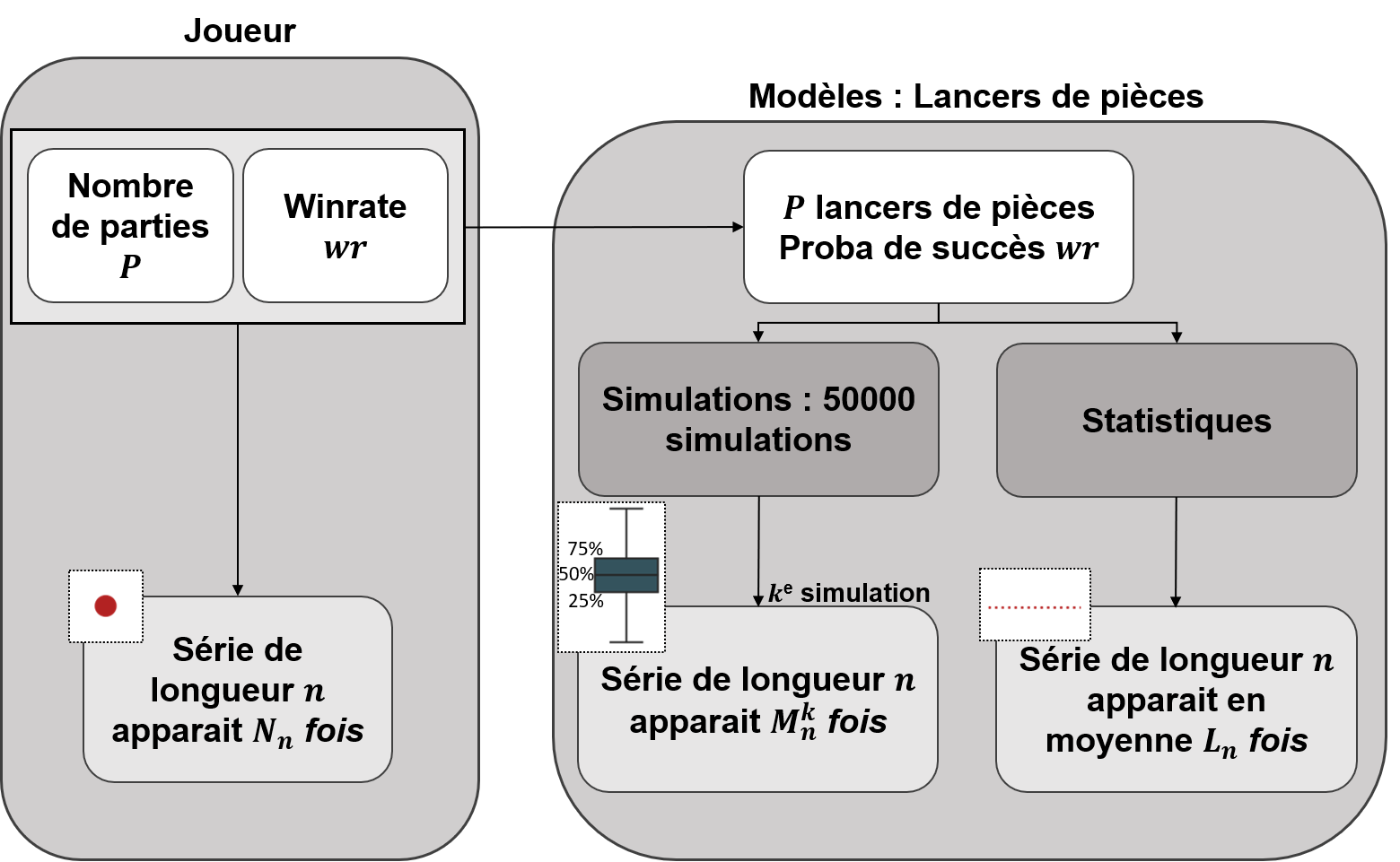
Pour une série de longueur n, nous avons donc trois valeurs à comparer. La valeur statistique calculée sert de valeur de référence à comparer avec les résultats du joueur. Les 50 000 simulations permettent de juger de la fiabilité des résultats à l’aide d’un intervalle de confiance empirique. Autrement dit, cela permet de visualiser la répartition de l’ensemble des résultats des simulations.
Résultats des joueurs
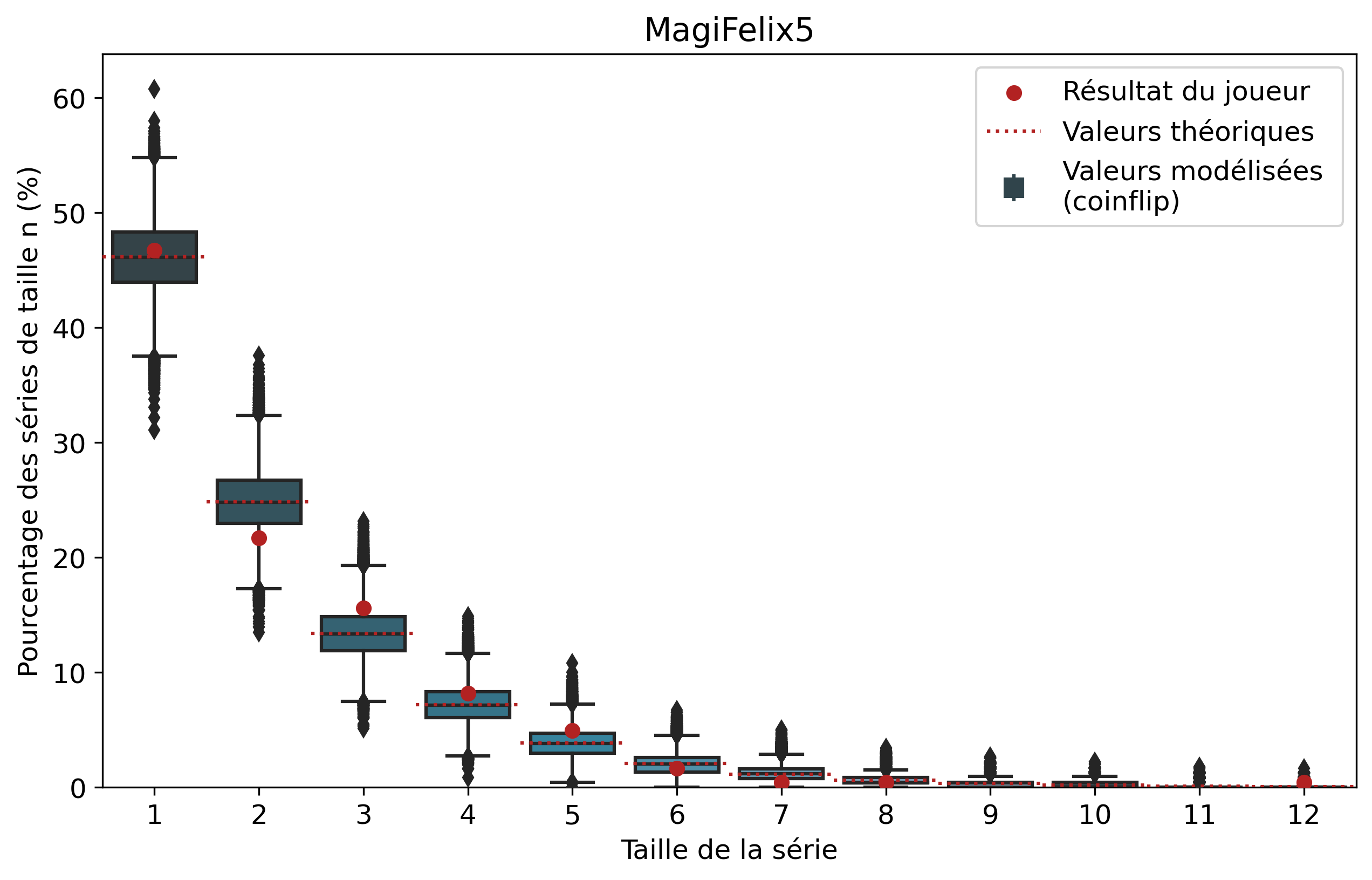
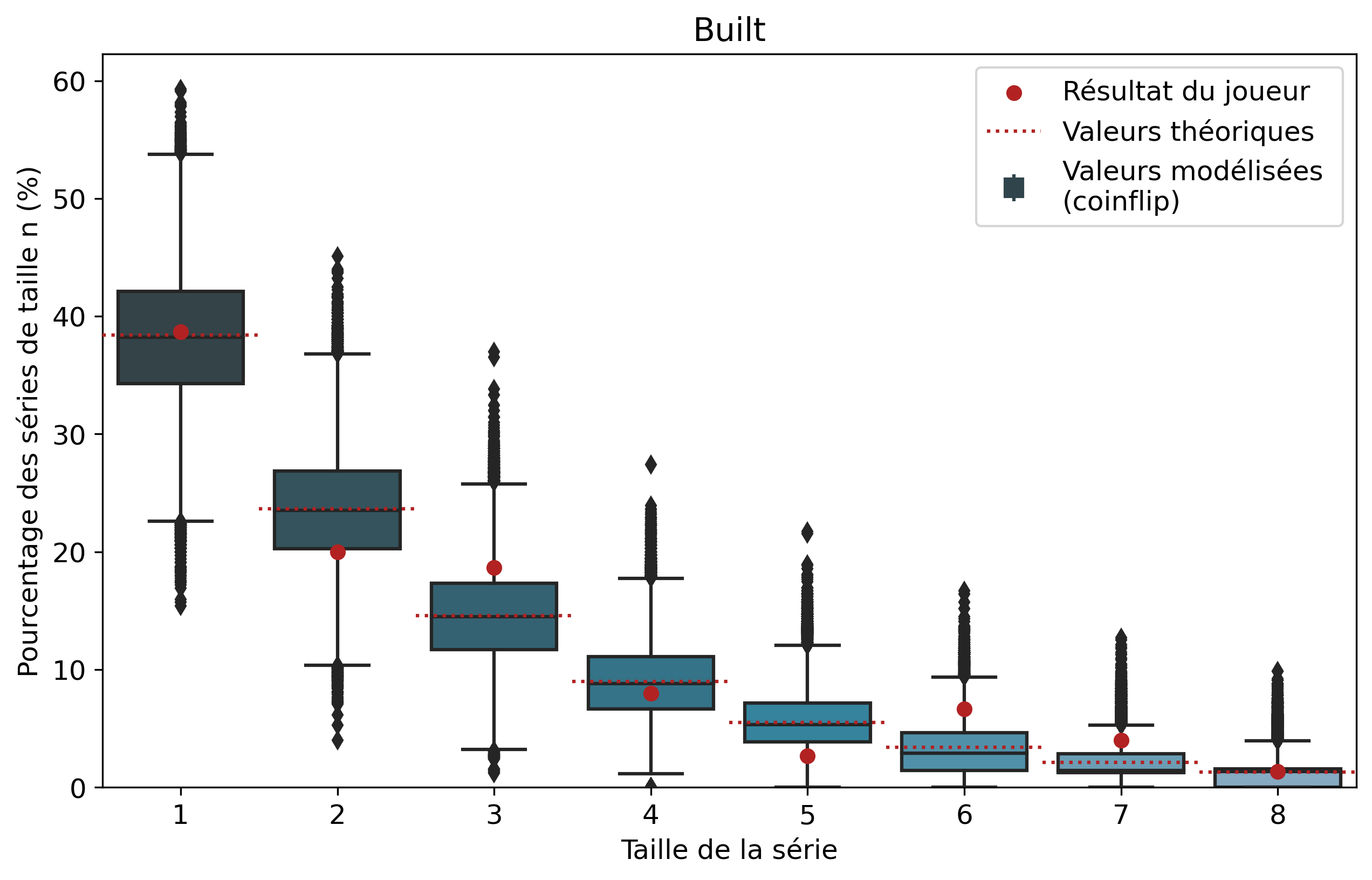
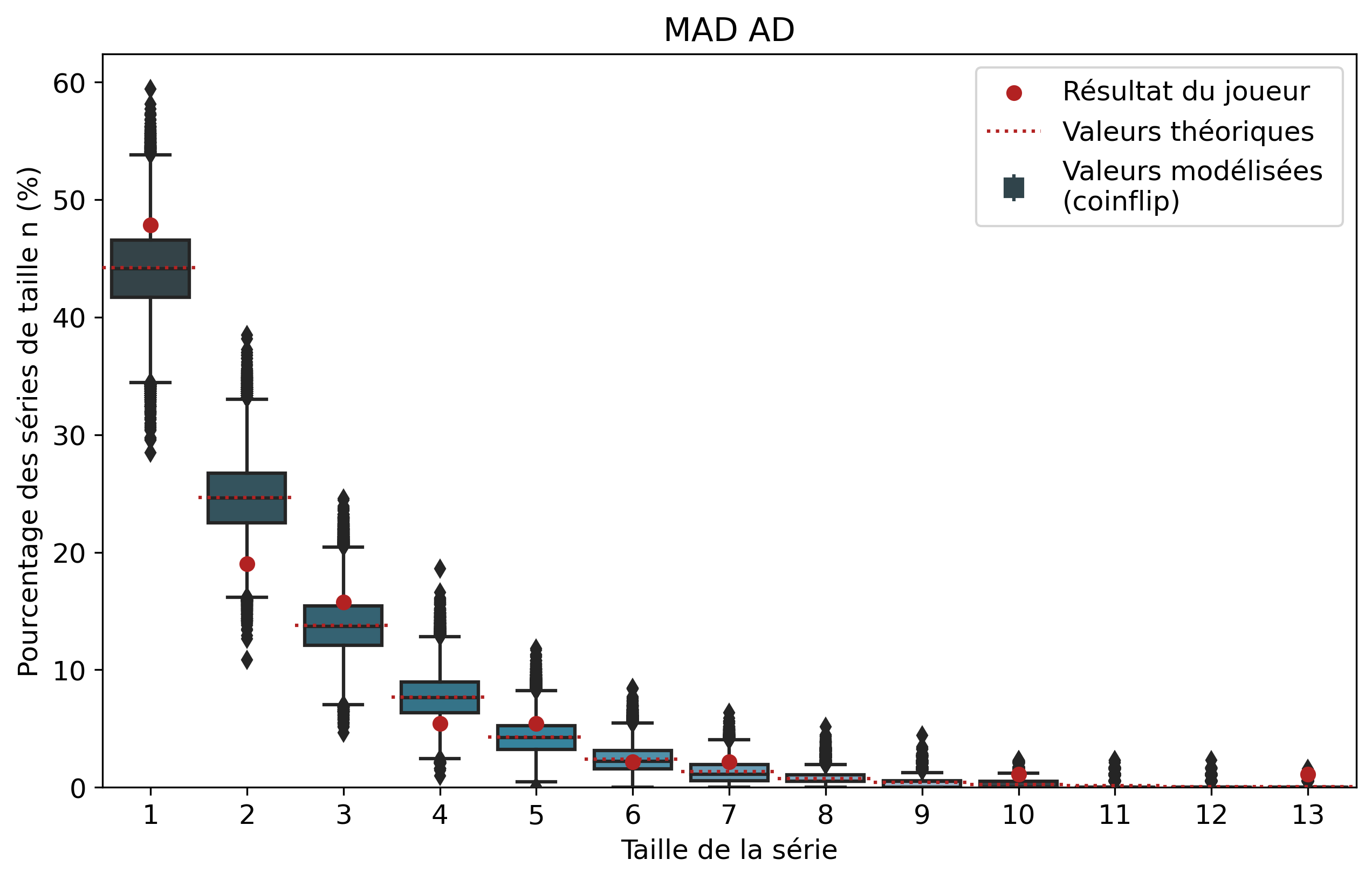
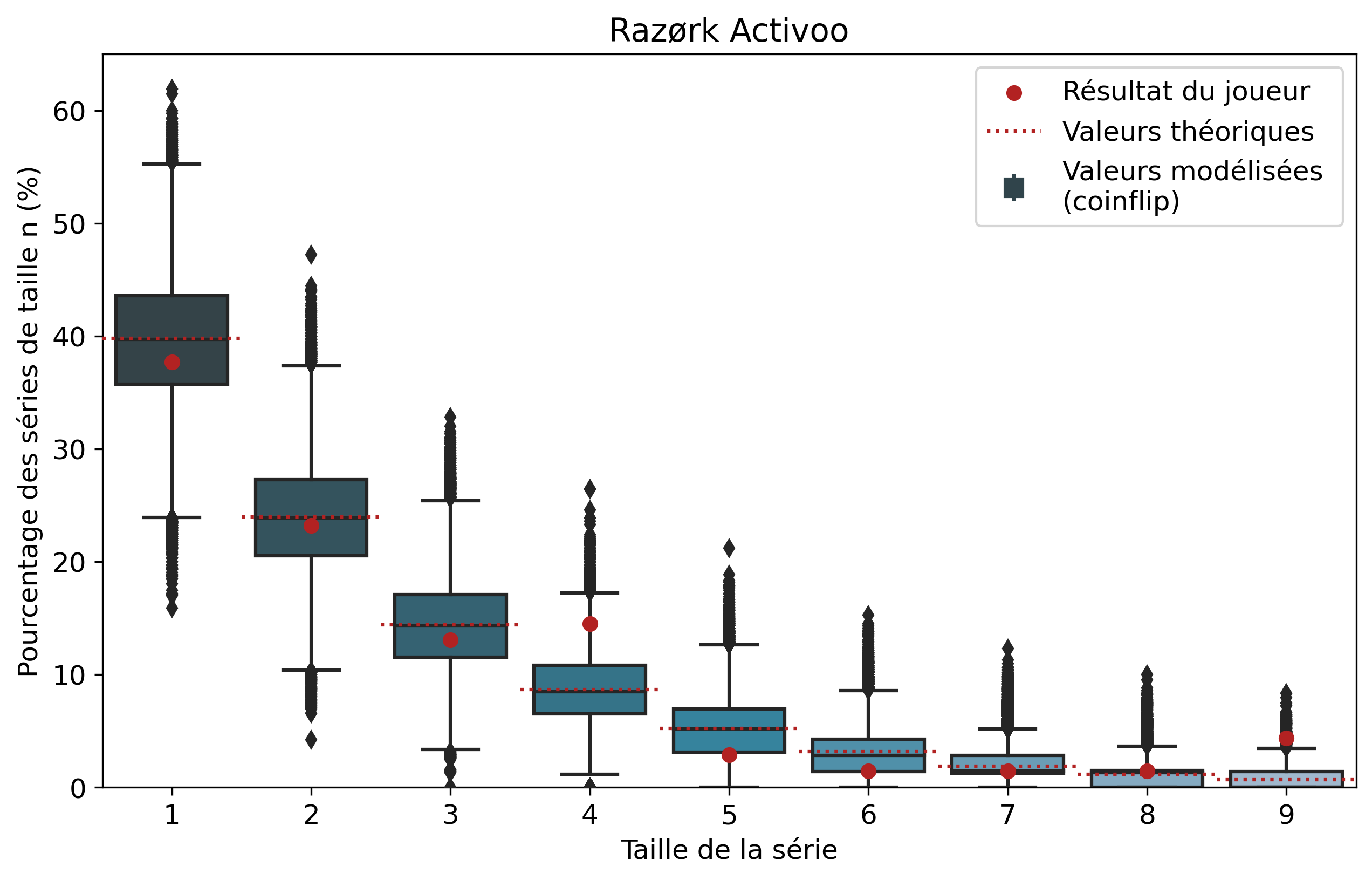
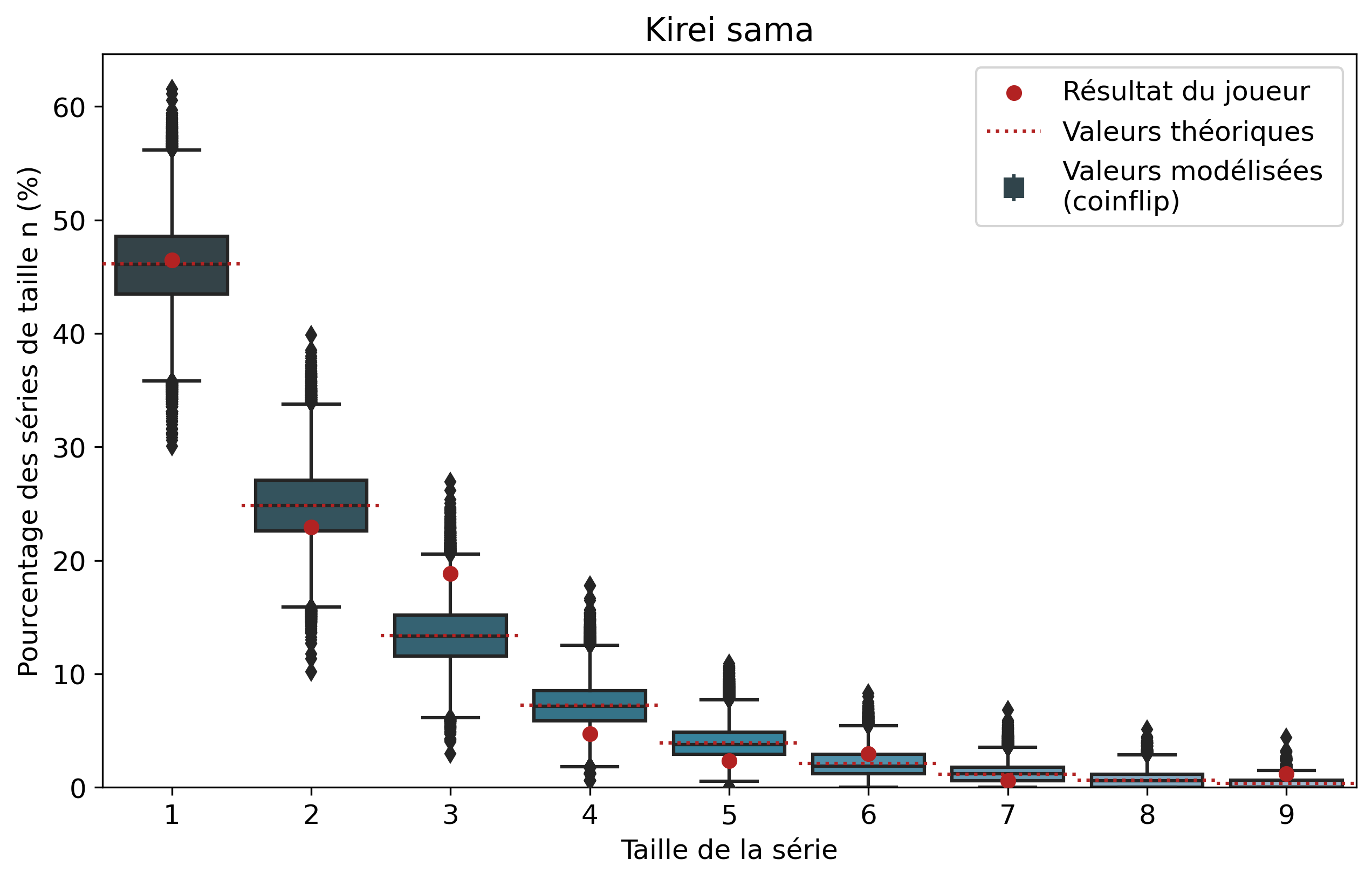
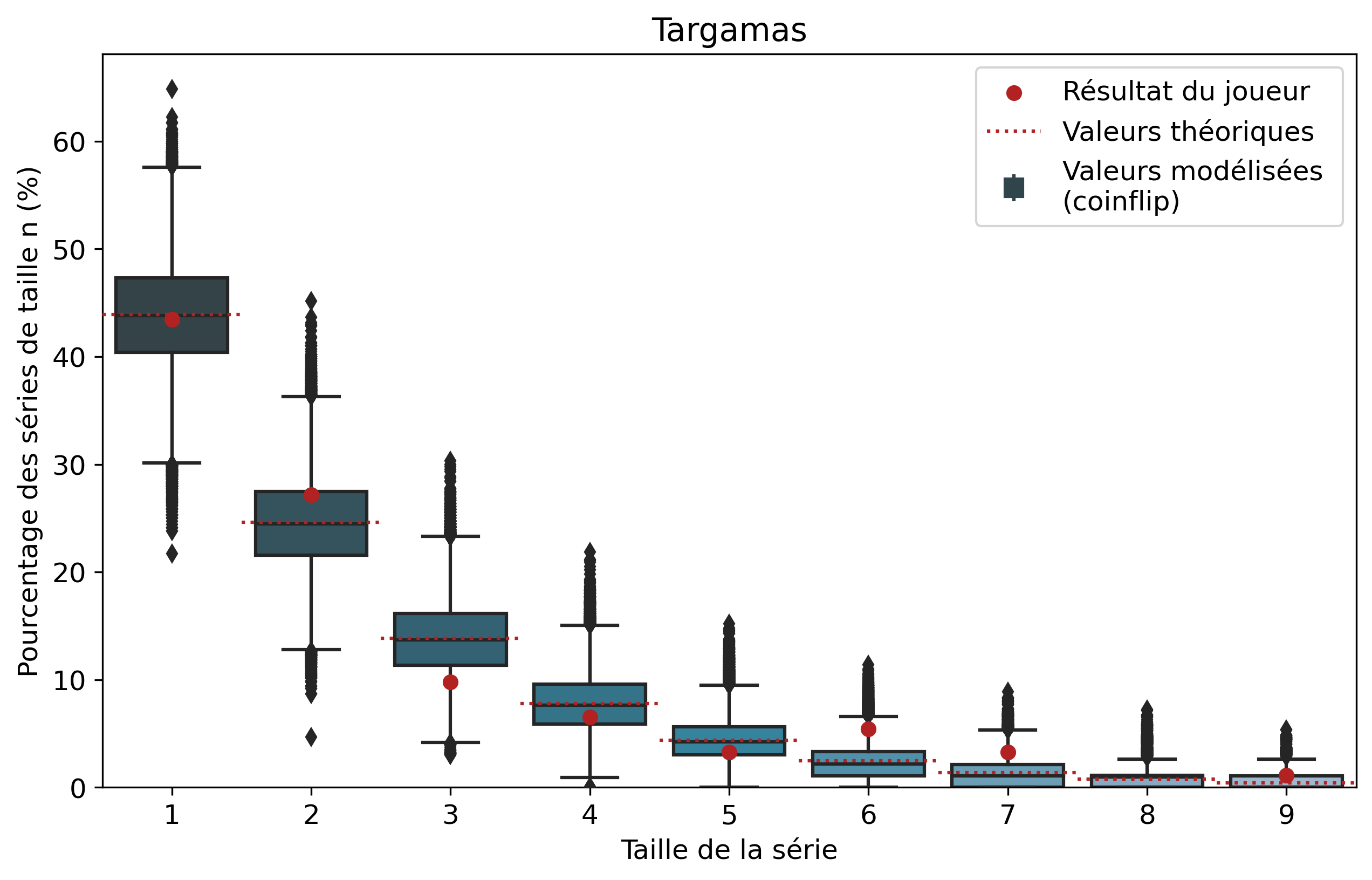
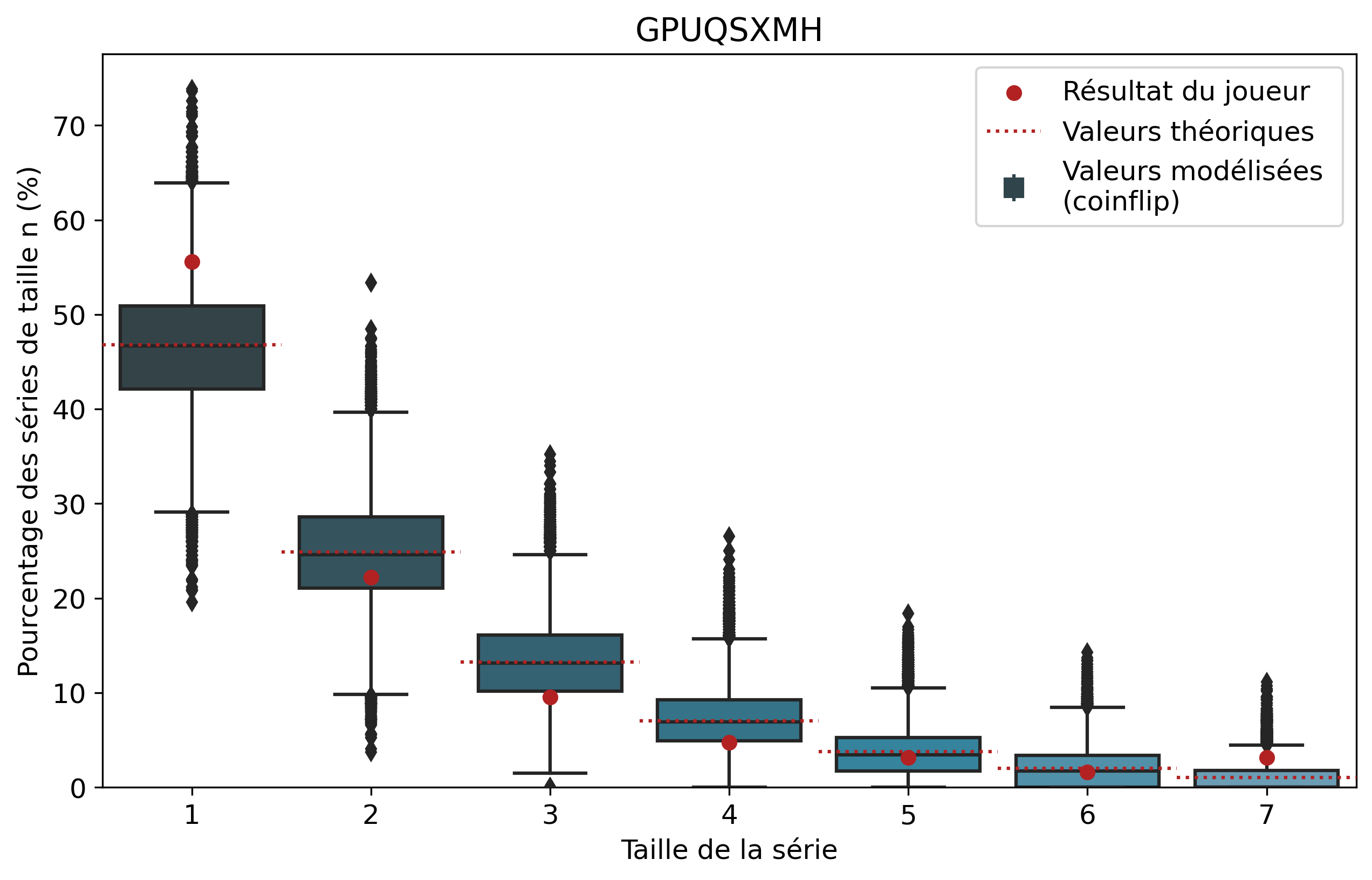
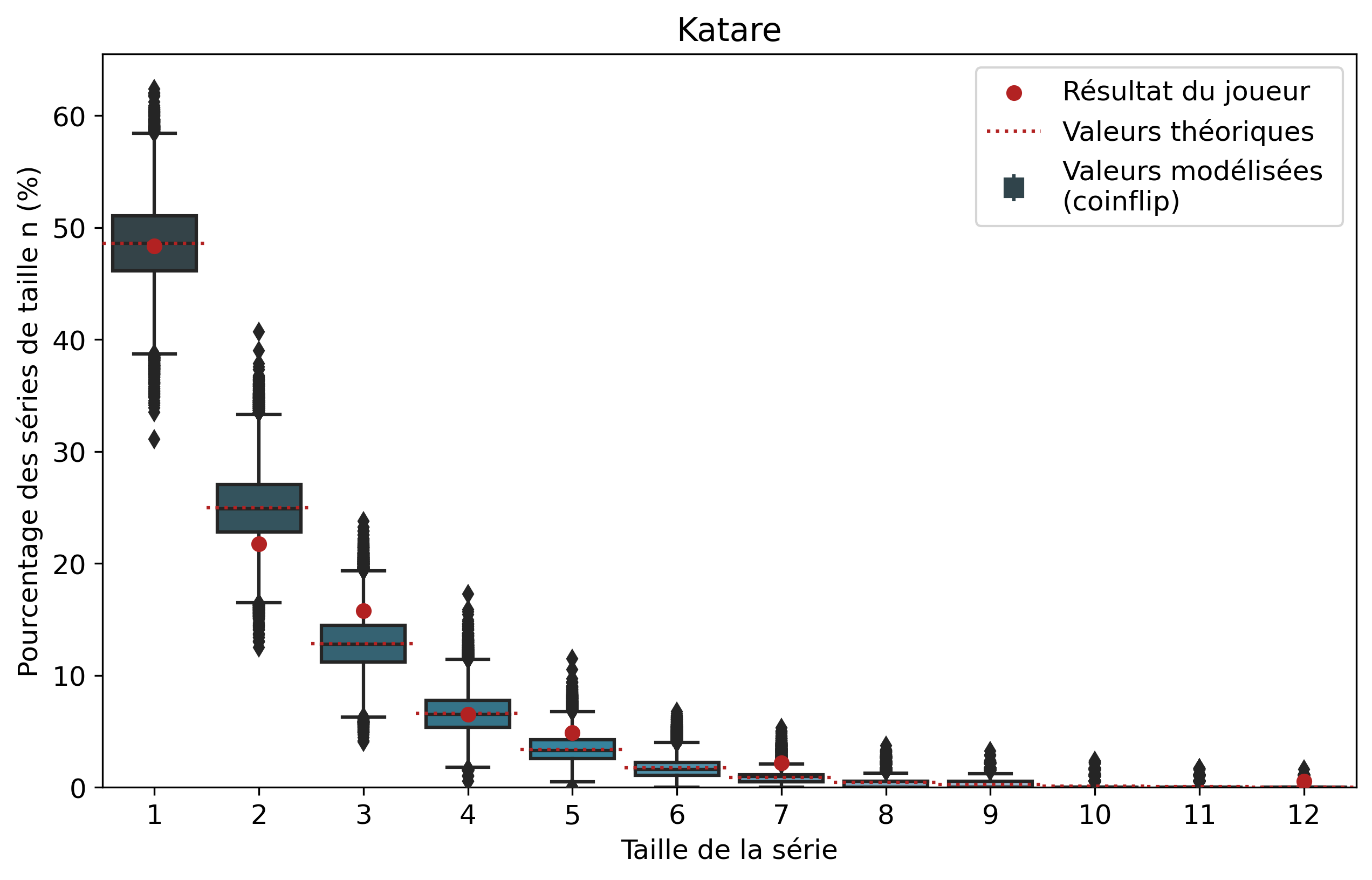
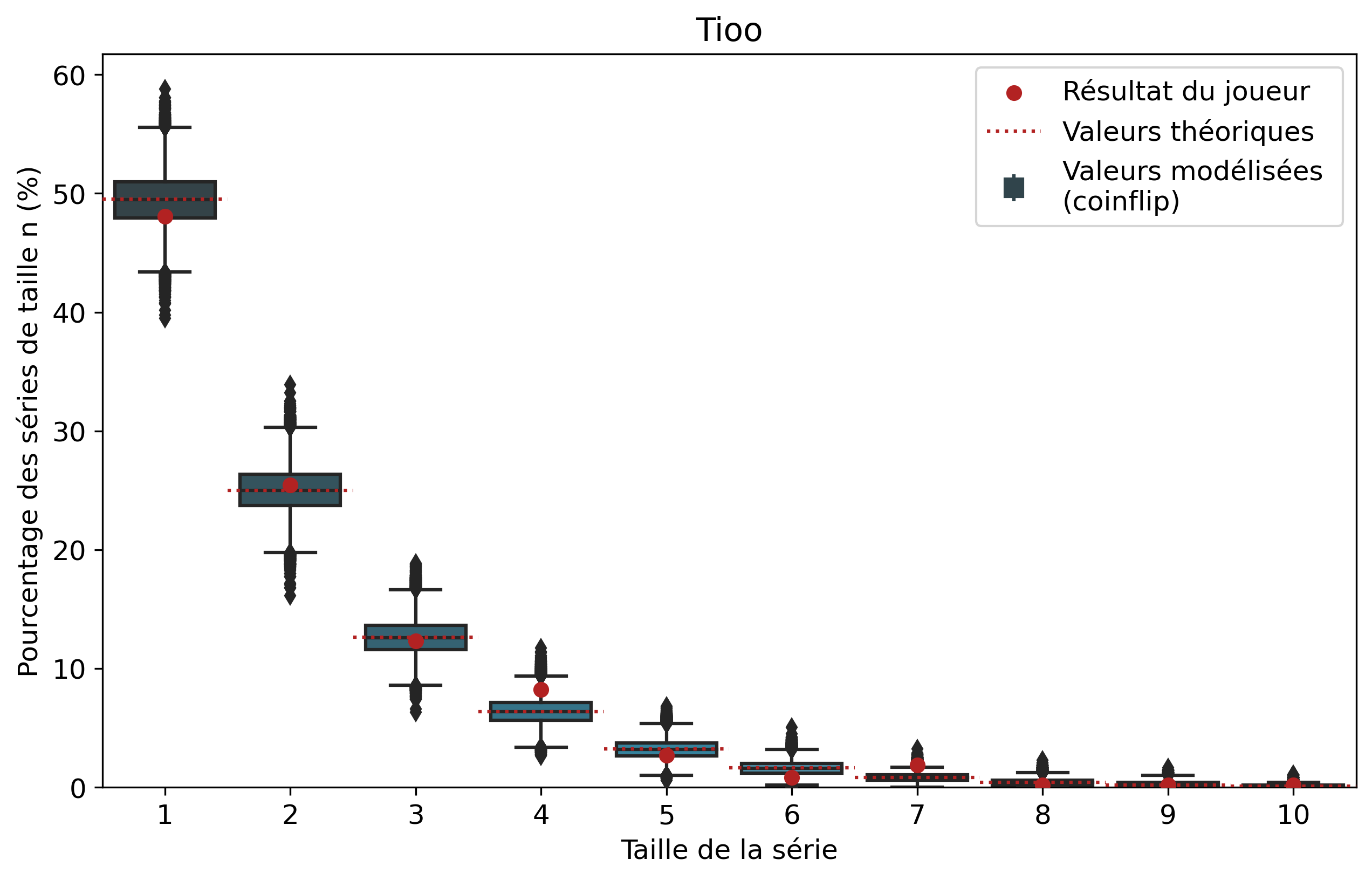
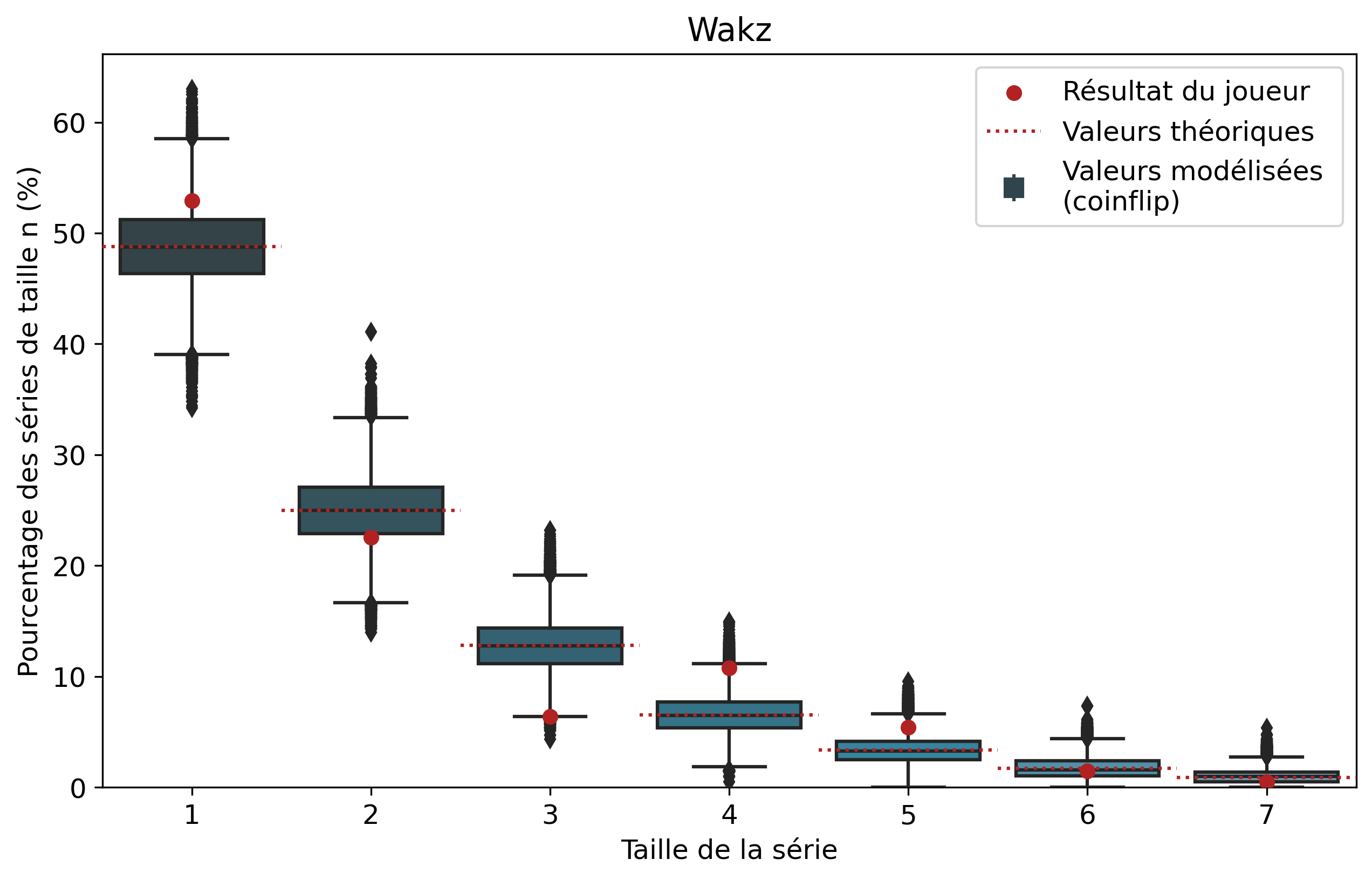
Comparons nos résultats à travers deux profils de joueurs assez différents. Tout d’abord, on peut remarquer que les deux modèles coïncident : la médiane des 50 000 simulations se superpose à la valeur moyenne déterminée par le calcul.
Si l’on se penche maintenant sur les résultats des joueurs, on peut remarquer que Nisqy (NISKING) reste assez proche de la valeur attendue. En revanche, Narkuss voit ses séries de 2 victoires assez largement au-dessus de la valeur attendue (mais restant dans un scénario « probable »). Cela pourrait indiquer une certaine tendance à gagner après une première victoire, ce qui est corroboré par la sous-représentation des séries de 1 victoire. Fun fact qui ne surprendra pas grand monde, chez Narkuss on retrouve également cette tendance dans la défaite.
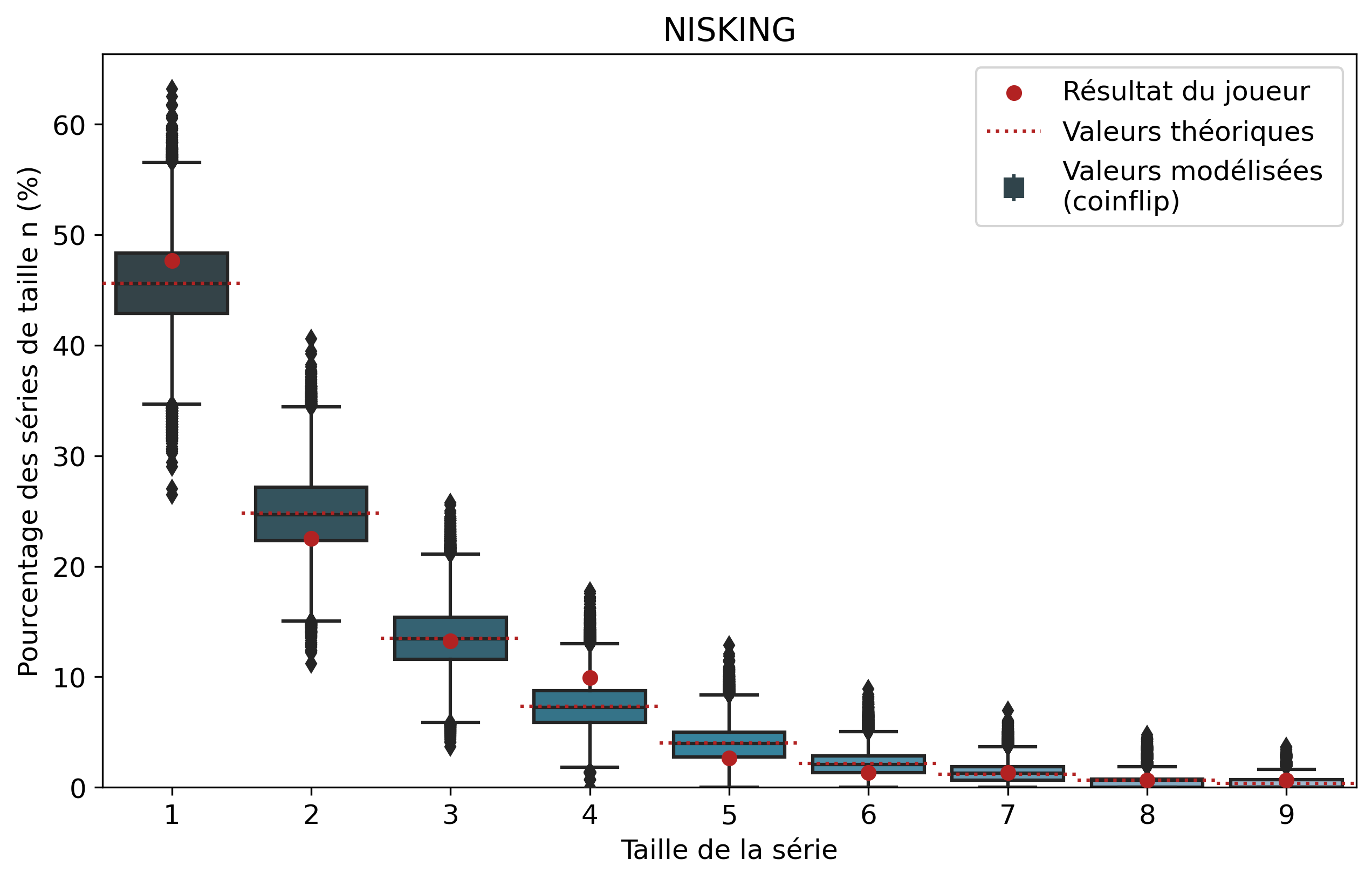
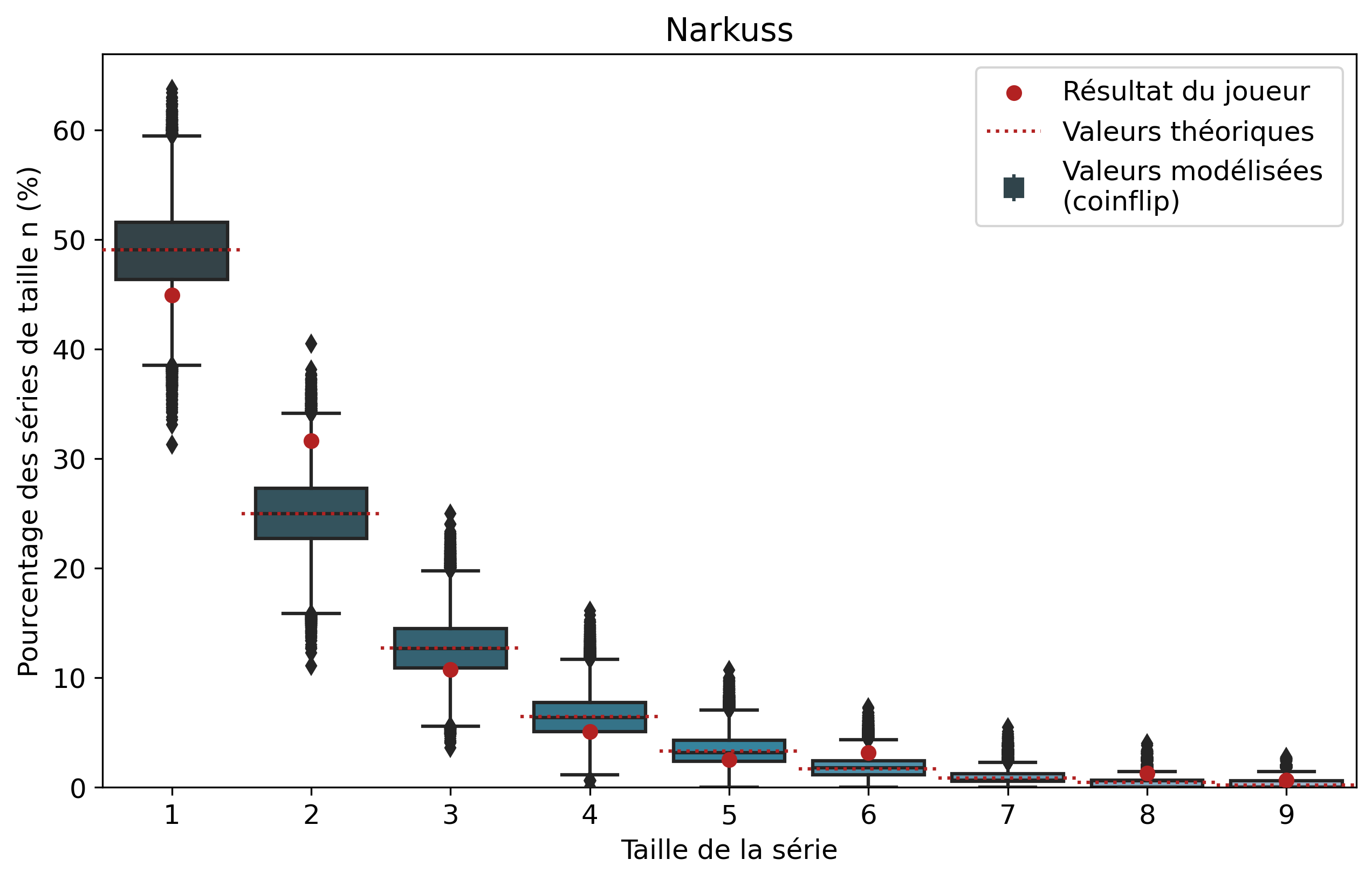
Il s’agit ici d’une des principales limites de notre modèle : en ne l’appliquant qu’à un seul joueur, on relève essentiellement ses biais. En revanche, si l’on compare plusieurs profils différents, les biais des joueurs tendent à se compenser et l’on peut s’intéresser à la présence d’un algorithme systématique qui favoriserait (ou non) les séries de victoires.
Résultats sur l'ensemble des joueurs
En comparant l’ensemble des résultats des joueurs avec leur valeur théorique respective, il est possible de remarquer une tendance intéressante. Tout d’abord la pertinence du modèle de pièces truquées : avec notre échantillon de joueurs, les écarts gravitent tous autour de zéro. Ce modèle, bien que simplifiant grandement la réalité complexe, est une approximation satisfaisante des séries de victoires. Si certains joueurs sont plus enclins à avoir de longues séries de victoires que d’autres, comparer les résultats de tous les joueurs nous amène bien à des résultats très similaires à ceux des pile ou face. En effet, cela permet logiquement de lisser les biais personnels des joueurs, ceux-ci finissant pas se compenser.
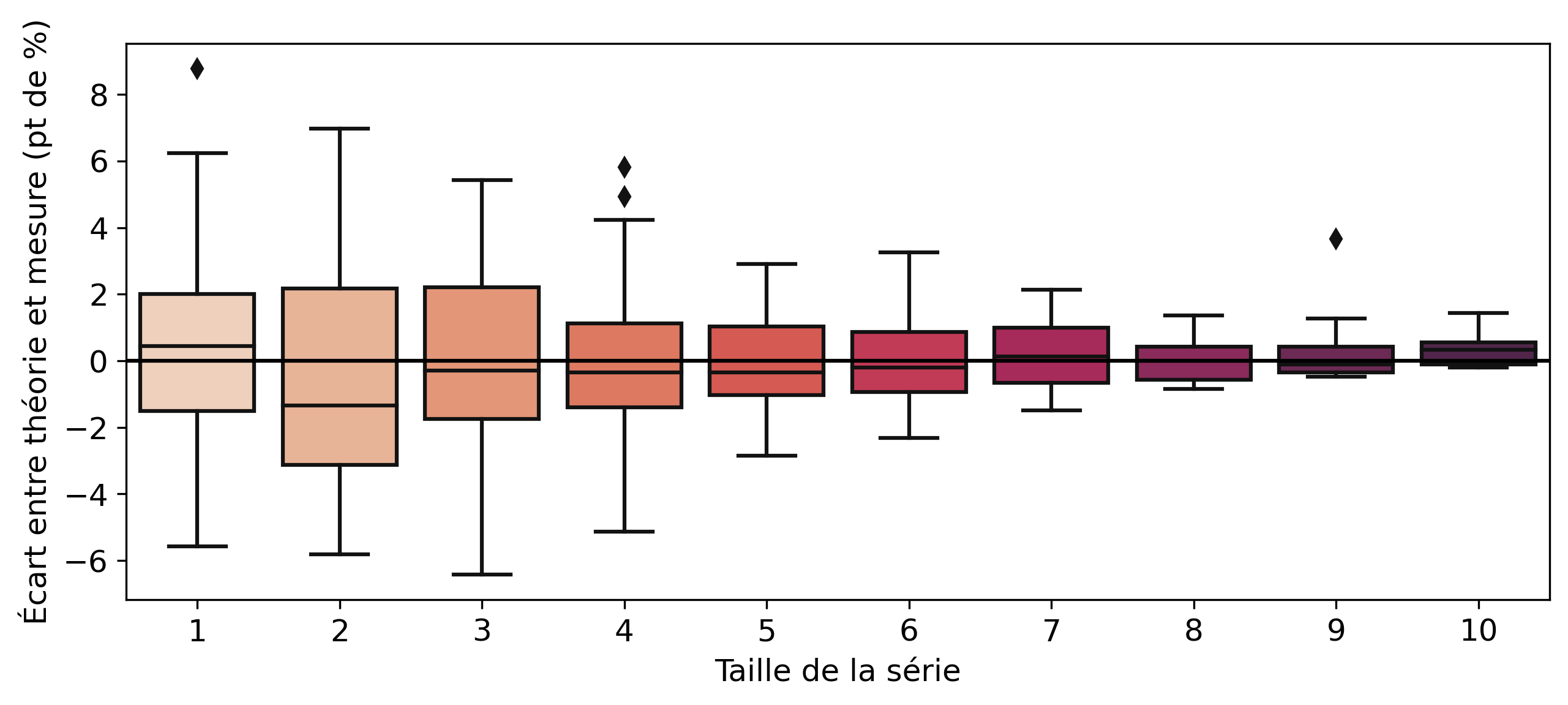
Le second point intéressant porte logiquement sur les conclusions concernant l’algorithme. On remarque que les écarts médians sont tous inférieurs à 2%. Sur notre échantillon de joueurs, il n’y a donc aucun biais systématique favorisant les longues séries de victoire. Les longues séries de victoires ou de défaites peuvent nous sembler plus présentes, car ces événements nous marquent plus que des séries courtes.
On peut également relever qu‘en moyenne, les séries de 1 victoire sont plus présentes que ce que prédit le modèle théorique. En effet, avec une médiane supérieure de 0.42 point de pourcentage à la théorie, les séries courtes sont légèrement surreprésentées. Cela pourrait laisser entendre que l’algorithme favoriserait davantage les séries courtes. Cependant les écarts statistiques sont trop faibles pour en tirer de véritables conclusions.
Conclusion
Ainsi, le mythe des longues séries de victoire favorisé par un algorithme est infondé. Pour augmenter l’implication d’un joueur, l’éditeur a tout intérêt à mettre en avant des séries courtes de victoires/défaites notamment en jouant sur des games de difficulté plus ou moins intense. Cela permet d’influer sur les cycles de frustration/récompense, comme le suggèrent les principes de l’EOMM, mais cela ne veut pas dire que les séries longues n’existent pas.
Par ailleurs, la comparaison des lancers de pièces avec les résultats des joueurs montre également que les similitudes peuvent considérablement varier selon le profil concerné. À l’échelle d’un joueur, les séries de victoires sont davantage favorisées par le playstyle ou le mental que par le matchmaking. Enfin, n’oubliez pas que tout cela se lisse, vous êtes le seul et unique point commun à l’ensemble de vos parties : il ne tient qu’à vous de leur insuffler une dynamique positive.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
7 commentaires
Dans le problème posé ici, la question principale étant : est ce que riot favorise les séries ? La question statistique ne devrait elle pas être Non-série (ou série de 1) vs Série (toutes cumulés) ?
La réflexion est : presque toutes les séries sont en dessous de la médiane et avec du pouvoir statistique en plus (vu que l’on regroupe toutes les séries), est ce que ça ne changerait pas la conclusion de l’article ?
Nous avons ici privilégié de tester les séries de différentes longueurs, la rumeur prétendant que « l’algorithme favorise les longue séries », cependant le principe même de « longue série » est particulièrement flou. Séparer les non-séries et les séries ne permettrait pas de répondre clairement à cette question. Au vu des résultats obtenus, ce regroupement ne changerait pas les conclusions de l’article.
Mais une analyse plus poussée pourrait permettre de savoir s’il y a véritablement une sur-représentation des non-séries par rapport aux séries et permettrait de répondre à une autre hypothèse concernant l’algorithme de matchmaking : « favorise-t-il l’alternance de victoire/défaite ? ». Pour aller encore plus loin, comparer les niveaux moyens de chaque équipe ou voir si les joueurs sensibles au tilt ont perdu leur game précédente pourraient représenter des approches plus complètes.
L’article n’a aucun sens à partir du moment où vous prenez des joueurs avec des winrates supérieure à 50%, qu’importe l’influence d’un quelconque algorithme, si ces joueurs sont meilleurs que leur opposant ils gagneront. Ce serait comme étudié exactement là même situation avec les statistique d’un master qui joue en silver et qui pulvérise toute les games malgré l’algorithme. Cela n’a strictement aucun sens à mon goût. Ce serait nettement mieux de faire la même étude avec des gold/plat voir diamant avec 1k 2k games. De plus il y a aussi le biais comportemental des personnes étudiées, comme par exemple Narkuss qui gagne plus souvent sa 2ème game de la journée si il a gagné la 1ère et inversement si il perd. Il faudrait aussi prendre en compte dans l’études l’honneur des alliées et des ennemies quand on gagne et quand on perd ( ptit brevet déposé par Tencent https://patents.justia.com/patent/11065547 ). Ce n’est pas pour rien que Tencent avait engagé des personnes spécialisé dans des domaines bien précis et qui travaillaient précédemment pour des algorithmes de jeu de casino. Penser qu’ils laissent la fonction la plus importante pour qu’un de leur « client » aka joueur reste actif sur le jeu à simplement de l’aléatoire est purement naïf. Je serais même pas étonnée que le nombre de ping + le type de ping utilisé influencerait de même que l’honneur pour le matchmaking des games tout comme les personnes qui se mettent à lancer une partie avec un rôle qu’ils ne jouent pas habituellement. Ce genre d’études est beaucoup trop soft pour pouvoir donner une bonne conclusion sur le sujet.
Effectivement, il est impensable de dire qu’il n’y a aucun algorithme derrière le matchmaking de LoL, simplement celui-ci ne semble pas favoriser les séries de victoire outre mesure, ce qui est ici le point de l’étude. Le winrate des joueurs n’est pas un soucis, la modélisation étant équilibrée de manière équivalente au winrate de chaque joueur. L’exemple du master qui pulvérise des games en silver ne tient pas la route tout simplement parce que même dans ce cas absurde, il serait possible de voir si ses séries de victoires sont incohérentes avec son winrate ou non, sans compter qu’il ne restera pas silver bien longtemps.
Je suis d’accord pour dire qu’il aurait été intéressant d’avoir un échantillon plus diversifié en termes d’élo. Sur l’ensemble des joueurs étudiés, des profils très différents se dégagent que ce soit en gameplay ou en résilience au tilt. C’est cette diversité qui est importante pour essayer de représenter au mieux une fraction des profils de joueurs. Cette diversité permet également de mieux comprendre comment certains comportements peuvent favoriser (ou non) les séries de victoires.
Enfin se baser sur des ressentis et des pures spéculations sur le fonctionnement du matchmaking comme par exemple qu’il utiliserait « les pings » n’a pas de sens. Je ne dis pas que c’est faux, juste que ce n’est pas l’objet de l’étude ici : on ne s’intéresse qu’aux séries de victoires et celles-ci sont statistiquement cohérentes.
N’en déplaise à ceux qui trouvent des défauts à ton article, et ils ont le droit bien sûr, t’as au moins fait l’effort d’une recherche avec un point de vue intéressant et encore jamais réalisé. C’est mille fois mieux que ceux qui se basent sur leur frustration après avoir int 5 games, bravo ! <3
Excellent, merci beaucoup ! C’est une telle étude qui manquait au débat, et il serait intéressant de la reproduire avec un plus grand échantillon de joueurs/parties.