Depuis quelques semaines déjà, il existe une polémique sur les réseaux sociaux qui oppose les artistes digitaux (graphistes, dessinateurs entre autres) aux IA comme Midjourney ou Dall-E. En effet, ces deux intelligences artificielles ont la particularité de pouvoir créer des dessins, des illustrations, à partir d’une simple phrase. Si vous voulez un dessin d’un éléphant rose qui fait du vélo, il vous suffit alors de donner cette phrase à une IA. Elle va vous générer en quelques secondes une image qui correspond quasi parfaitement à vos attentes.
J'ai demandé à Midjourney de me faire un éléphant rose sur un vélo, voici le résultat après 40 secondes d'attente.
Un énorme problème donc pour les artistes qui voient leur travail volé par des programmes. Mais également un outil très puissant pour d’autres, permettant de créer des œuvres à moindre coup et surtout en très peu de temps. A titre d’exemple, un mangaka japonais a pu créer un début de manga (link) à partir de planches générées par IA.
Il va sans dire que créer des planches de ce style prendrait normalement beaucoup de temps et d’argent. L’IA a donc peut être un rôle à jouer. Quel que soit votre avis sur la question, nous allons dans cet article tenter de comprendre comment fonctionnent ces IA.
Disclaimer : Il va de soi que les définitions que nous allons voir sont vulgarisées puisqu’elles sont surtout destinées à vous permettre de comprendre l’article.
Qu'est ce qu'une IA ?
Avant de rentrer dans le vive du sujet, il est important de comprendre de quoi on parle. Le terme « IA » (Intelligence Artificielle) ne veut en réalité pas dire grand chose. On aime bien utiliser ce terme pour justifier son expertise informatique, parce que ça claque un peu plus que « programme ». En revanche il existe deux autres termes bien plus intéressants pour définir ce que sont des programmes « intelligents ».
Intelligence Artificielle
« Une IA est un programme informatique capable d’imiter un comportement humain. »
Machine Learning
« Un programme informatique dit de machine learning est une IA capable d’apprendre. C’est à dire qu’avant d’être considéré comme fonctionnelle, un tel programme doit s’entraîner. »
Deep Learning
« Le deep learning définit tout programme de machine learning qui utilise un ou plusieurs réseaux neuronaux pour fonctionner.
Note : Malgré l’utilisation du mot neurone, le Deep Learning est loin de reproduire le fonctionnement du cerveau humain. Les neurones artificiels ne font que s’inspirer de loin de leurs homologues biologiques, plus complexes.
Comme nous l’avons vu, en réalité « IA » est un terme très général. De plus, il est important de noter que le deep learning est une sous catégorie du machine learning. Un programme de deep learning est forcément du machine learning. Et ces deux architectures sont des sous-ensemble du terme « IA ».
Dall-E et Midjourney sont des programmes de deep learning. Ils utilisent à un moment donné un ou plusieurs réseaux neuronaux. Il ne s’agit donc pas d’une simple IA comme les start-upers parisiens peuvent vous vendre.
La problématique
Comme je vous le disais, tout programme de machine learning a besoin d’une phase d’entraînement (que l’on appelle phase d’apprentissage) avant d’être opérationnel. Il existe deux grandes “familles d’entraînement” largement utilisées dans le domaine aujourd’hui : l’apprentissage supervisé et l’apprentissage non supervisé (que l’on pourrait expliquer dans un prochain article).
Dall-E et Midjourney ne font pas partie de ces deux catégories et sortent des sentiers battus pour deux raisons :
L'absence de base de données
Pour s’entraîner, il faut une base de données. Pour apprendre à une IA à reconnaitre une image de chat, il nous faut des dizaines de milliers de photo de chat, et d’autres photo qui ne sont pas des chats. Et dans notre cas, à savoir générer une illustration à partir d’une phrase, nous n’en avons pas.
En effet, vu que l’on peut créer une phrase avec n’importe quelle combinaison de mot, il est difficile d’avoir exactement une base de données correspondant à notre phrase. Croyez le ou non, les bases de données d’éléphants roses faisant du vélo ne courent pas les rues. Le problème est donc que le sujet n’est pas fixe.
Nécessité de résultats aléatoires
On pourrait demander à une IA entrainée par un apprentissage non-supervisé de dessiner des illustrations. Mais il y a des très fortes chances qu’elle dessine quasiment toujours la même chose. Ici, n’oublions pas que Dall-E et Mid Journey vous sortent plusieurs images provenant de la même phrase. Il faut donc introduire une notion d’aléatoire dans les résultats.
L'algorithme de plongement
Le premier problème a été résolu en réalité il y a déjà une dizaine d’années, quand l’IA débutait ses compréhensions écrites et ses générations de textes. Il s’agit de l’algorithme de plongement.
Pour comprendre, reprenons notre exemple fil rouge : « Un éléphant rose sur son vélo »
1 - Traduire une phrase en une liste de mots-clés
« Un éléphantrosesur son vélo »
La première étape est plutôt simple. Éléphant, rose, vélo sont évidents, mais ici il ne faut pas oublier « sur » qui indique une information sur la position.
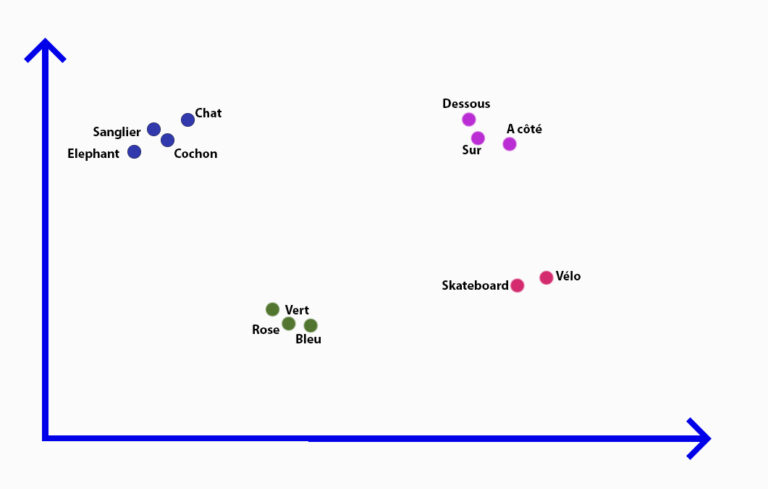
2 - Placer les points dans une espace vectoriel
La deuxième étape consiste à placer les mots dans un espace vectoriel. Deux mots qui se ressemblent sont proches l’un de l’autre dans l’espace. Voici un exemple tout simple en deux dimensions :
Ici pour comprendre, il n’y a que 2 dimensions. Les IA peuvent en gérer plusieurs centaines.
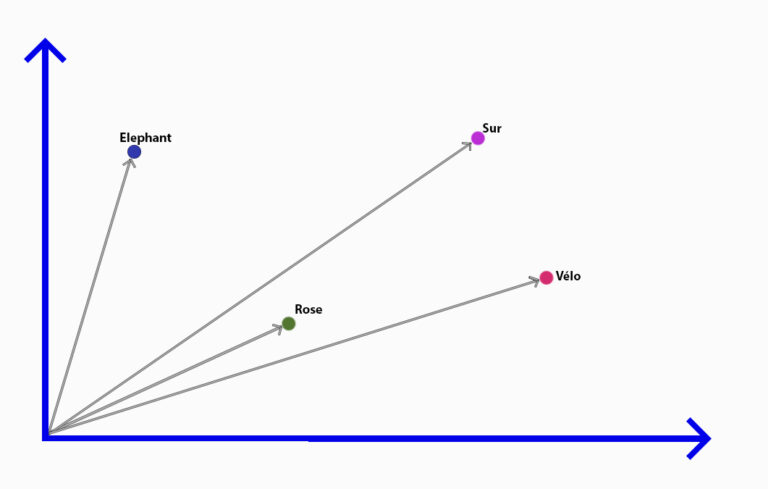
3 - Représenter la phrase un vecteur
Ensuite, les mots vont être assemblés pour former un vecteur représentant la phrase. Le vecteur est ici représenté par les flèches grises.
Notre vecteur est en réalité une suite de nombres qui représentera la phrase pour l’ordinateur. L’astuce est d’utiliser ce vecteur pour aller piocher dans une base de données contenant des images ayant des vecteurs proches. Ainsi, avec une seule (énorme) base de données , on peut seulement piocher les photos pertinentes ! Notre problème de base de données et de sujet pas fixe est donc résolu.
L'algorithme de diffusion
Depuis 2014 et les travaux de Ian Goodfellow, Midjourney et Dall-E utilisaient des GAN (Generative Adversarial Network) pour contourner notre problème d’aléatoire dans nos résultats. Leur principe était d’entrainer deux IA à se tromper l’une l’autre, l’une devant générer des photos et l’autre devant deviner s’il s’agissait d’une vraie photo ou d’une générée.
C’est notamment grâce aux GAN que nous devons l’extraordinaire site this person does not exist. Il génère des visages de personnes à partir d’une énorme base de donnée.
La personne sur cette photo n'éxiste pas et a été généré par une IA entrainé par un GAN.
Mais la petite révolution, et sans doute le cœur de cet article, c’est la création et l’amélioration récente des algorithmes de diffusion pour remplacer les GAN, pas si efficace que ça dans notre contexte. Cet algorithme a pour but de régler notre deuxième problème : générer des images différentes et introduire une notion d’aléatoire dans nos résultats.
En réalité, le principe est assez ingénieux, il s’agit de « simplement » dé-bruiter des images.
Voici Hélios à gauche, et voici Hélios avec du bruit à droite. Jusque là, rien de bien sorcier.
La première étape est d’entrainer une IA (avec un apprentissage supervisé) à dé-bruiter les images. C’est à dire qu’avec une base de donnée contenant des millions de chats, en plus du même chat bruité, l’IA doit apprendre à enlever le bruit. L’exemple ci dessous pourrait être une paire parmi les millions de notre base de données. Il est également important d’ajouter l’élément « chat » à ce dé-bruitage pour que l’IA puisse en plus savoir quel élément elle dé-bruite.
L’idée en plus est de pouvoir préciser à notre IA un pourcentage de bruit que l’on souhaite retirer. Ainsi on ne passe pas directement à une image nette en sortie, mais de 70% à 45% par exemple. De cette façon, on peut demander 20 fois à notre IA de dé-bruiter une image de quelques % pour obtenir notre résultat. Et chaque résultat sera en partie aléatoire. En effet, chaque « demande » à l’IA de dé-bruitage de quelques % est indépendante. Elle n’a aucune idée de ce qu’a fait la demande précédente et de ce que fera la suivante. Chaque demande à l’IA va donc créer le chat à sa façon et ajouter sa patte, de façon aléatoire.
Dans cet exemple, j’ai re-demandé à Midjourney mon éléphant rose sur son vélo, et j’ai pu screen 4 étapes du défloutage.
Au final
Midjourney et Dall-E sont au final un assemblage de plusieurs IA de deep learning utilisant un algorithme de diffusion, et un algorithme de plongement.
1 – Votre phrase est d’abord analysée par une première IA qui la transforme en un vecteur (algorithme de plongement). 2 – On prend une image complétement bruitée 3- On demande à notre IA de dé-bruitage de la dé-bruiter de quelques % plusieurs fois en conditionnant le dé-bruitage par le vecteur (algorithme de diffusion). Votre phrase (vecteur) sert en quelques sorte à sélectionner les images d’inspirations dans la colossale base de données à disposition.
Et voilà ! Vous avez désormais une idée plus claire sur le fonctionnement des IA et plus particulièrement de Dall-E et Midjourney ! N’hésitez pas à consulter nos autres articles sur SWTCH :
Je ne suis pas sûr d’avoir saisi votre question, mais j’imagine que vous parlez de l’image de la base de donnée. Si c’est le cas, je n’avais pas la réponse, et j’ai cherché sur internet. La base de donnée qu’utilise Midjourney semble être LAION https://en.wikipedia.org/wiki/LAION
La sélection de l’image se fait via les vecteurs, comme j’essaye d’expliquer dans l’article. Chaque image est associé à une série de milliers de nombres qui la représente. Chaque nombre est « associé à un concept ». Par exemple on peut associer le premier nombre de cette liste à « rouge », le deuxième à « forme ronde », etc …
La sélection de l’image initiale est donc une image dont le vecteur est proche de celui demandé par l’utilisateur avec sa phrase.
Quand dans l’article, je demande un éléphant rose, il est probable qu’il prenne en base une photo d’un objet rose imposant (bien plus probable qu’une telle image existe déjà). Par exemple, un chewing gum rose géant ou zoomé. Les vecteurs de « chewing gum rose géant » et de « éléphant rose faisant du vélo » devraient être plutôt proches. Donc c’est le chewing gum rose qui devrait être flouté, puis servir de base pour déflouter et créer mon éléphant rose sur un vélo.















3 commentaires
Bonjour
Merci pour cet article
Question : d’où provient l’image « nette » qui a servi à obtenir l’image bruitée ?
Comment est-elle sélectionnée ?
Merci
Bonjour Eric et merci votre commentaire.
Je ne suis pas sûr d’avoir saisi votre question, mais j’imagine que vous parlez de l’image de la base de donnée. Si c’est le cas, je n’avais pas la réponse, et j’ai cherché sur internet. La base de donnée qu’utilise Midjourney semble être LAION https://en.wikipedia.org/wiki/LAION
La sélection de l’image se fait via les vecteurs, comme j’essaye d’expliquer dans l’article. Chaque image est associé à une série de milliers de nombres qui la représente. Chaque nombre est « associé à un concept ». Par exemple on peut associer le premier nombre de cette liste à « rouge », le deuxième à « forme ronde », etc …
La sélection de l’image initiale est donc une image dont le vecteur est proche de celui demandé par l’utilisateur avec sa phrase.
Quand dans l’article, je demande un éléphant rose, il est probable qu’il prenne en base une photo d’un objet rose imposant (bien plus probable qu’une telle image existe déjà). Par exemple, un chewing gum rose géant ou zoomé. Les vecteurs de « chewing gum rose géant » et de « éléphant rose faisant du vélo » devraient être plutôt proches. Donc c’est le chewing gum rose qui devrait être flouté, puis servir de base pour déflouter et créer mon éléphant rose sur un vélo.
Merci Tapir.
Ceci répond à ma question
Merci
Eric